译注:强化学习简介(第 4 部分)
- 说明
- Reinforcement Learning: An introduction (Part 4/4)
- 开发环境配置(Development Environment Setup)
- 抽象化强化学习环境(The RL Environment Abstraction)
- 实现 REINFORCE(Implementing REINFORCE)
- 总结(Conclusion)
说明
本文是对 Cédric Vandelaer 强化学习简介(Reinforcement Learning: An introduction)系列译注。仅供学习交流之用!
原文包含 4 部分,此是第 4 部分。
原文链接:Reinforcement Learning: An introduction (Part 4/4)
原文作者:Cédric Vandelaer
Reinforcement Learning: An introduction (Part 4/4)
欢迎回到强化学习(Reinforcement Learning,RL)简介系列的最后一部分。

在最后一部分中,我们将亲自动手实现在第 3 部分中讨论过的 REINFORCE 算法。在此之后,您将拥有一个可工作的算法,可用于解决一些简单的任务。最重要的是,您应该对策略梯度算法有适当的了解,您可以使用它来解决更复杂的问题和算法。
今天讨论内容的如下:
- Development Environment Setup(开发环境配置)
- The RL Environment Abstraction(抽象化强化学习环境)
- Implementing REINFORCE(实现 REINFORCE)
- Conclusion(总结)
让我们深入了解一下!
开发环境配置(Development Environment Setup)
每个开发者首先需要的就是一个开发环境。我不想强制执行任何特定的设置或工具,但如果您是初学者,我将引导您了解我个人使用的工具。
集成开发环境(代码编辑器)IDE(Code editor)
我选择的代码编辑器是 Visual Studio Code。它是一个轻量级编辑器,可用于多种编程语言。该编辑器开箱即用,它本身提供非常少的工具,但允许您通过扩展添加更多功能。

Python
我们将使用一种高级编程语言 Python 进行编程。我们所说的高级是指该语言会为您处理很多事情,例如内存管理。它也是一种解释型动态类型语言。您可以像任何其他应用程序一样下载并安装 Python。就我个人而言,我使用 3.8 版本以获得与多个库的最大兼容性,但对于本教程,您可以继续安装最新的可用版本。
虚拟环境配置(推荐可选)Virtual environment setup (Optional, recommended)
在本教程中,我们将使用一些库(导入到我们项目中使用的代码)。通常通过包管理器安装这些库。对于 Python,默认的包管理器称为 pip。我们将使用 pip 安装一些软件包。然而,创建一个所谓的虚拟环境是一个好主意。虚拟环境将您安装的软件包与其他(虚拟)环境隔离。进行这种隔离通常是一个好主意,因为它允许您同时安装包的多个版本(但在不同的环境中)。
创建虚拟环境有多种好处,而且实现方法也有多种。现在我们只看一种特定的方式。我们首先打开一个终端。导航到您想要放置代码的文件夹并键入以下命令:
1 | # For Windows |
这告诉 Python(版本 3.X)创建一个名为 env 的新虚拟环境。接下来,我们需要使用以下命令激活此环境:
1 | # For Windows |
就这样!从现在起,您输入的命令将在您的虚拟环境中执行。要停用环境,只需键入 deactivate 即可。要再次激活环境,只需键入上述命令即可。请确保您位于与创建环境的文件夹(您的项目文件夹)相同的文件夹中。
PyTorch
在下一步设置中,我们将安装深度学习框架。有许多可用的框架,但在撰写本文时的行业标准是 TensorFlow 或 PyTorch。我们将使用后一种,尽管没有什么可以阻止您选择 TensorFlow(或其他框架)。

在之前的文章中,我们讨论了神经网络、梯度等。PyTorch 将为我们抽象出很多这些概念,并提供现成的实现来让我们的生活更轻松。
为了安装 PyTorch,您需要打开一个终端并输入此网站上提供给您的命令:
https://pytorch.org/get-started/locally/
您应该选择 Stable、您的操作系统、Pip、Python 和 Default。
其他包(Additional packages)
我们将使用的一些较小的其他 pip 包是:
您只需使用 pip install <nameofpackage> 即可安装它们。
抽象化强化学习环境(The RL Environment Abstraction)
为了训练我们的强化学习算法来解决“任何”问题,我们将对环境进行抽象。为此,我们将使用 OpenAI 提供的流行框架 Gym:
您可以像上面的链接中的任何其他 pip 包一样安装 Gym 框架。至关重要的是,Gym 为我们提供了几个抽象可以应用于任意环境和问题:
- 您可以使用
gym.make(“environment-name”)函数创建环境 - 创建环境后,您可以使用
env.step(action)行操作并进入下一个状态。此函数将为您提供对下一个状态(state)的观察(observation)、获得的奖励(reward)、指示回合(episode)是否结束的布尔值以及一些可选的元数据(metadata) env.reset()函数会将环境重置为起始状态(并返回此起始状态的值)- 最后,
env.close()函数将清理环境分配的所有资源
我们将比使用 vanilla Gym 更进一步。我们将编写自己的 Environment 类,其中包含一些附加变量和辅助函数,这对我们以后实现更复杂的算法有很大帮助。
实现 REINFORCE(Implementing REINFORCE)
现在,我们将开始编写一些代码。首先,我们需要一个可以代表我们的策略的类(神经网络,Neural network)。
神经网络(Neural network)
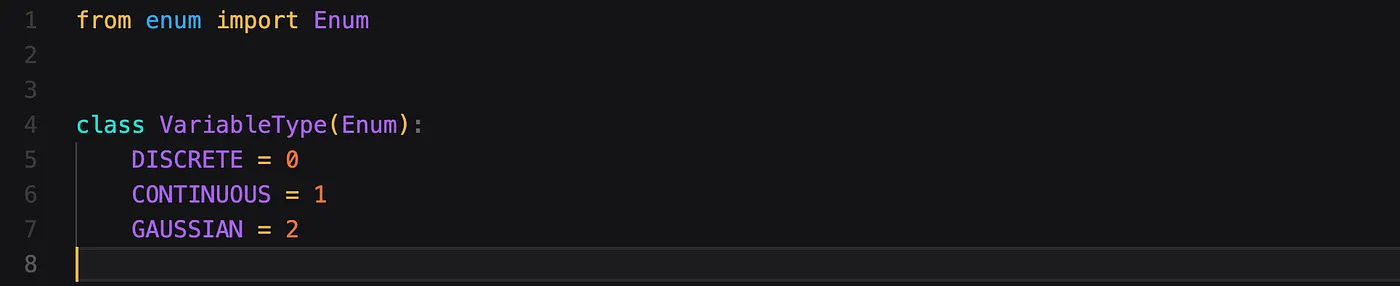
首先定义一个小的枚举。这个枚举用来区分我们期望的不同类型的神经网络。
- Discrete (离散)表示离散输出(discrete output),或更准确地说是固定维度数量上的概率分布。
- Continuous (连续)表示连续值。
- Gaussian (高斯)表示高斯分布输出(gaussian distribution output),这意味着我们输出平均值(mean)和标准差(standard deviation)。
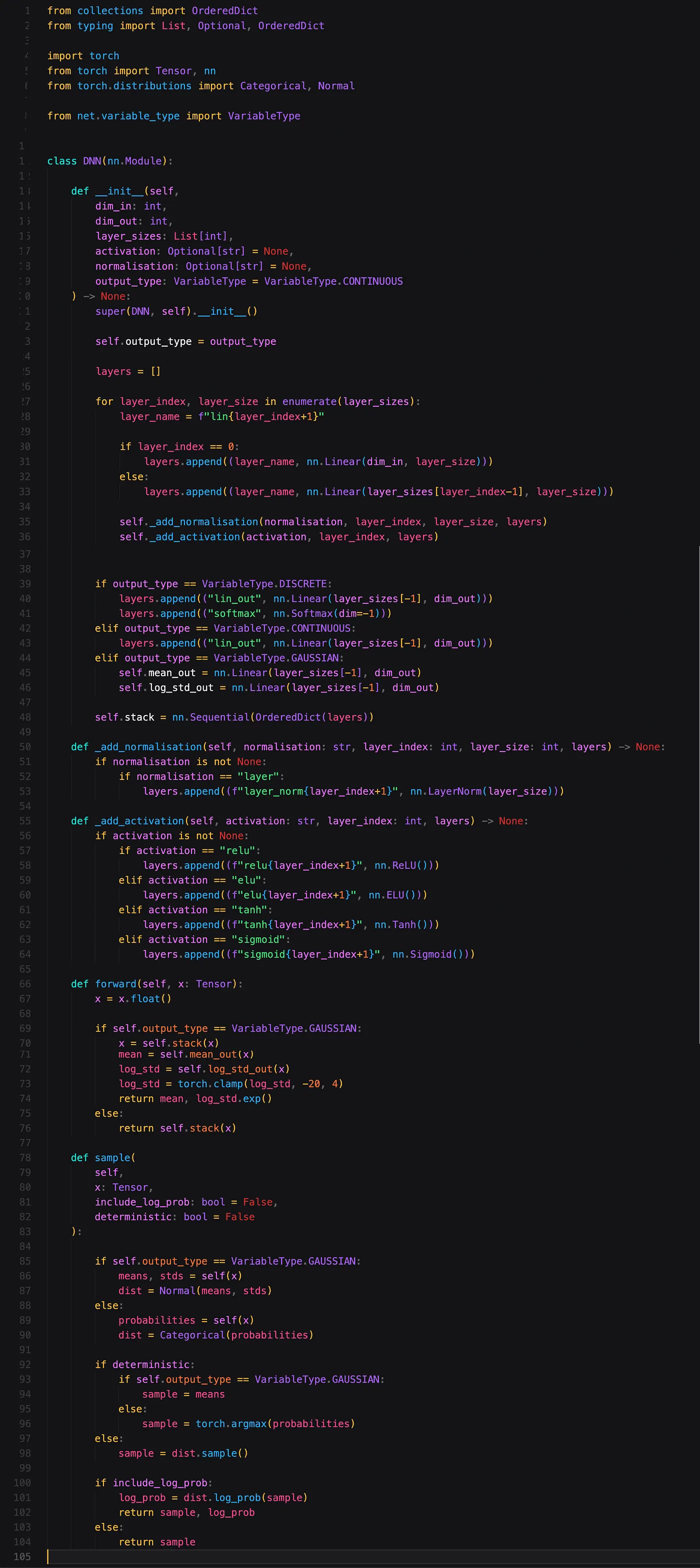
下一个 class 代表我们的神经网络。我们从一个相当复杂的构造函数(__init__ 函数)开始。尽管有很多代码,但这个构造函数所做的只是在给定一些配置的情况下构造一个神经网络。最关键的参数是 dim_in、 dim_out 和 layer_sizes。它们分别表示输入维度大小、输出维度大小和隐藏层中神经元的数量。
接下来有一个 forward 函数,这是 PyTorch 中的典型函数。该函数对我们的神经网络进行前向传递(如果您想了解有关 PyTorch 如何处理神经网络的更多信息,请参阅 此处 的资源)。
最后我们有一个 sample 函数。该函数通过网络执行前向传递,构建分布(分类分布或高斯分布),然后从中获取样本。您可以选择传递一个称为 deterministic(确定性)的布尔值,在这种情况下,将返回高斯的平均值,或者分类分布最高的维度的索引。
环境
如前所述,我们还将在 Gym 抽象之上创建我们自己的抽象环境。这样做是为了让实验变得更容易,这样我们就可以编写更少的代码来尝试不同的环境。稍后,这种抽象还将帮助我们实现一些更复杂的算法,这些算法需要覆盖一些函数(例如,如果我们需要自定义 reward-function(奖励函数))。
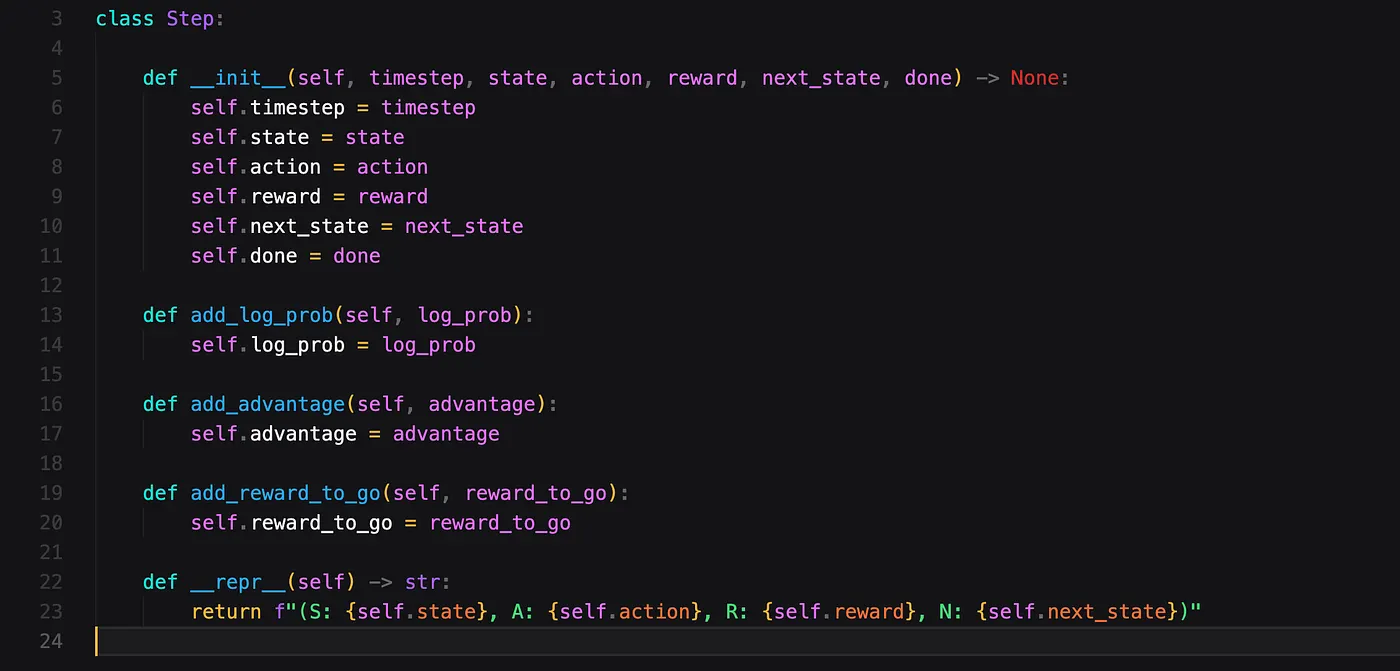
我们从一个简单的 Step 类开始,它代表环境中的一个步骤。本质上,Step 类只是一个数据容器类。

我们的 Trajectory 类包含一系列 Steps。除此之外,它还包含一些辅助函数,用于将这些步骤包含的值转换为张量(Tensors)。Tensor (张量)是 PyTorch 中的数据对象,它将使我们的计算更加高效。它还包含一个辅助函数来计算轨迹的得分(score)和长度(length)。

我们定义一个 ActionType 枚举,以区分需要离散行动空间(discrete action space)或连续行动空间(continuous action space)的环境。
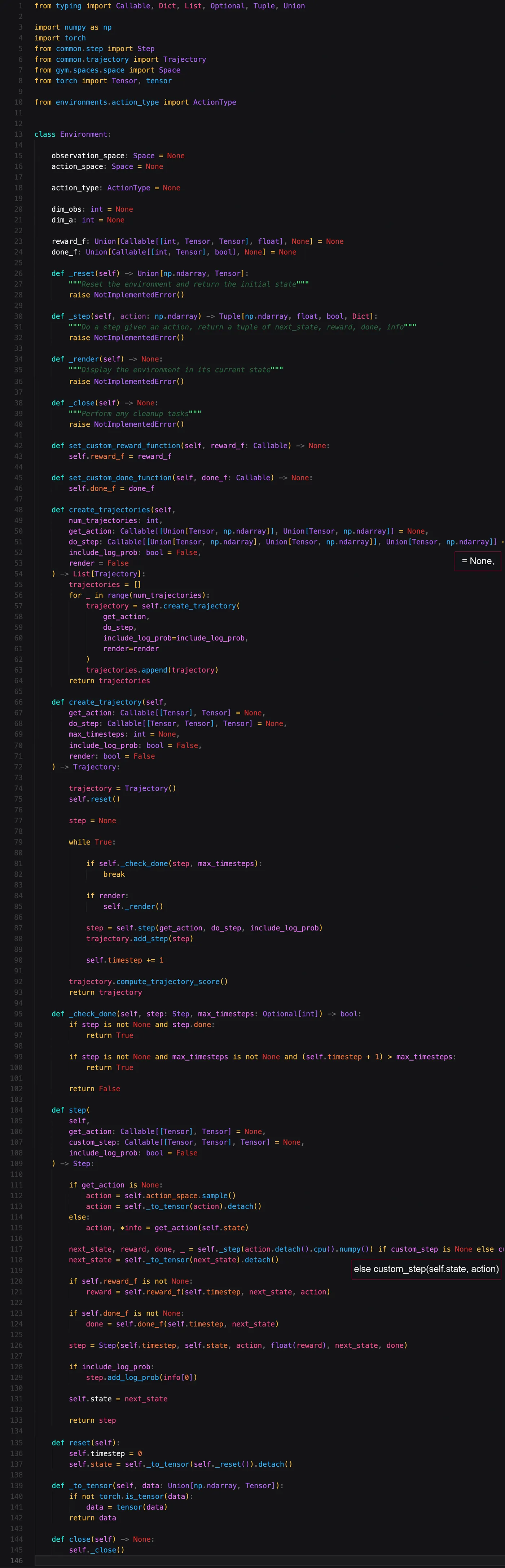
下一类是我们实际环境的抽象。定义了一些变量,例如状态空间(state space)的维度(注意:当前仅支持向量)、行动空间(action space)的维度和行动类型(type of actions),以及通常的 Gym 抽象。我们还允许用户传递一些函数作为参数。它们允许用户覆盖 reward-function(奖励函数)或如何确定回合(episode)何时结束。
最重要的两个函数是 create_trajectory 和 step。前者会输出环境中的轨迹,后者在环境中执行一步。在某些情况下两者都可能有用。
如果您想将该类与 OpenAI Gym 提供的环境之一结合使用,可以使用以下继承自 Environment 类的类来实现。
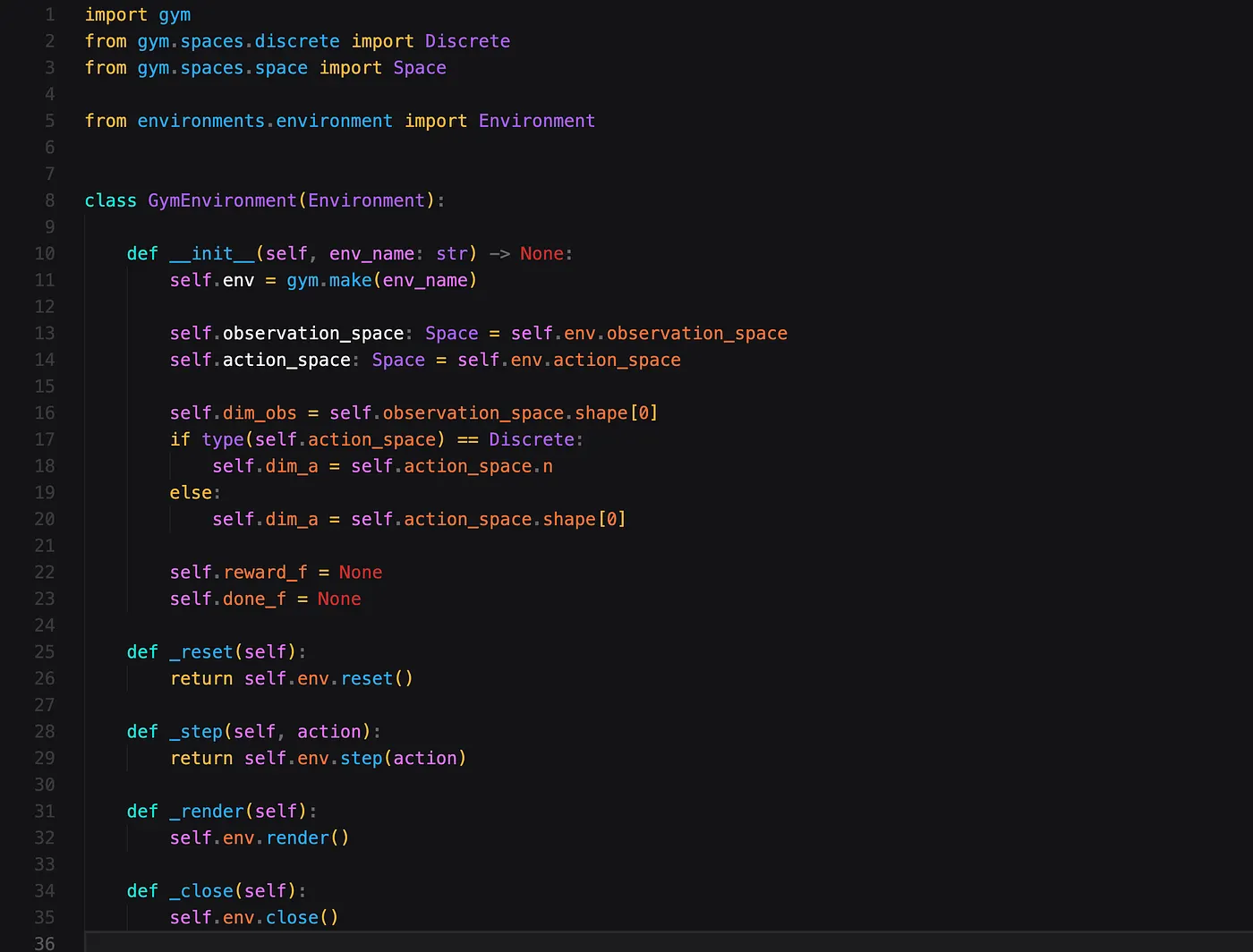
为了在其中一种环境(例如 Pendulum-environment(摆锤-环境))中使用此功能,您可以按照与此示例类似的方式进行操作。
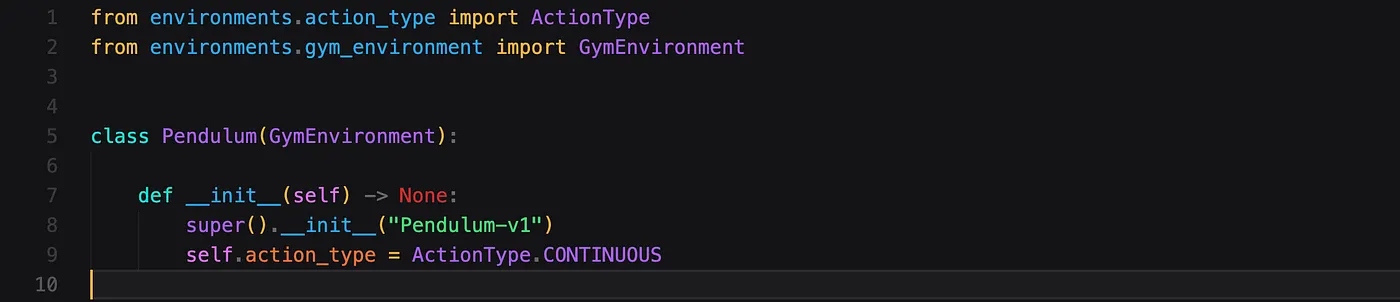
基线计算(Baseline calculation)
正如我们在上一篇博文中所看到的,我们还需要计算 reward-to-go。我已将此代码作为名为advantages.py的文件的一部分,因为理论上该值应与 advantage 类似,并且我们可能希望稍后将其重用于其他算法。
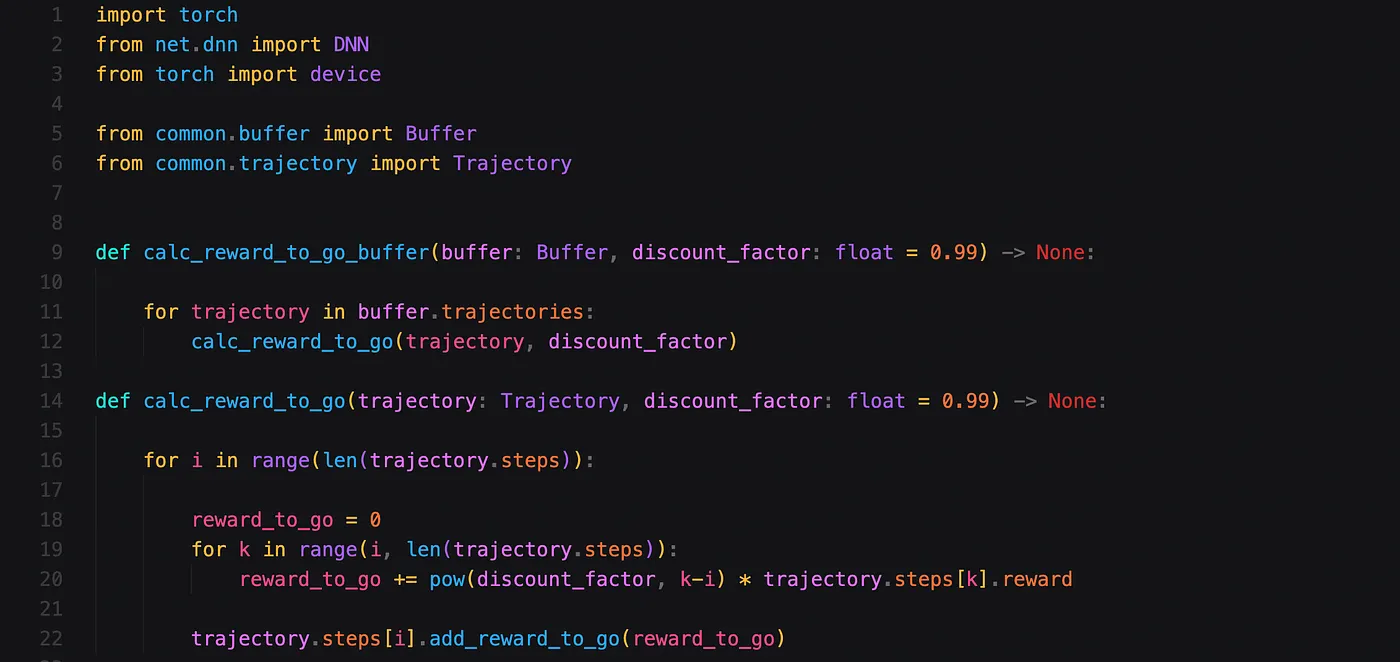
该文件还提到了一个我们稍后将其用于其他算法的缓冲(buffer),但您现在可以安然地忽略它。reward-to-go 计算以 trajectory(轨迹)和 discount_factor(折扣因子) 作为输入。您可能需要根据正在解决问题未来奖励(future rewards)的重要性或不重要性来调整折扣因子。
记录器(Logging)
为了确保看到一些输出并可以跟踪智能体的表现,我们将编写一个执行一些评估(evaluation)的类。
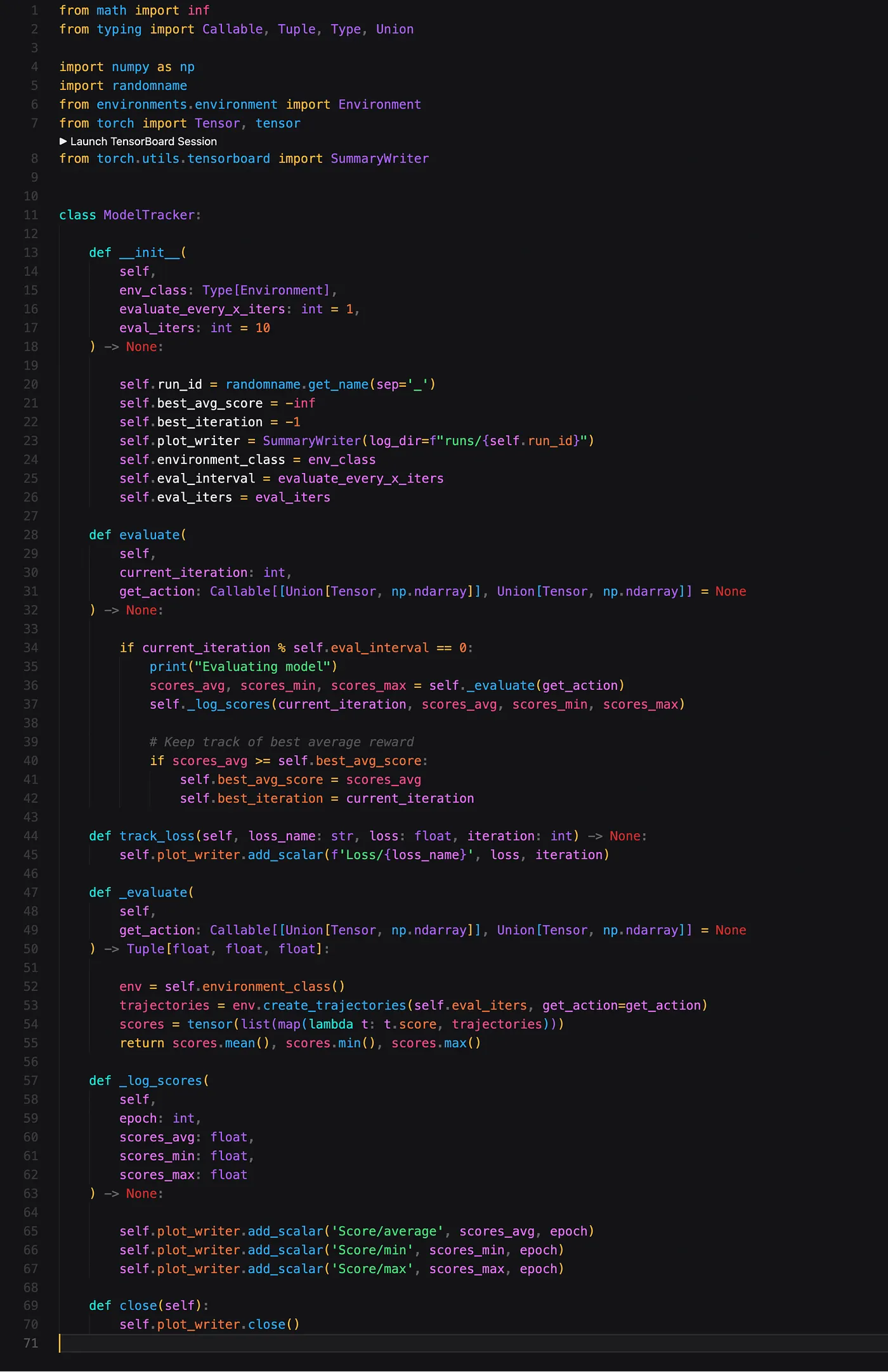
如您所见,我们在此类中使用 Tensorboard 库。这将使我们能够通过带有一些漂亮仪表板的图表来跟踪(track)算法的进度。
记录器的关键(crux)在于 _evaluate 函数。这里我们利用 Environment 类来创建几个轨迹。为了创建这些轨迹,我们传入一个名为 get_action 的参数。 get_action 参数是一个函数,它将状态(state)作为输入,并生成行动(action)作为输出。这可能看起来很通用,确实如此,但这正是我们希望它能够在我们想要评估的方面提供最大灵活性的方式。
通常,get_action 参数是一个函数,它使用强化学习的智能体来确定下一个行动(action)(给定状态,given the state)应该是什么。
强化算法(Reinforce algorithm)
然后我们实现实际算法。在此版本中,我们在每次梯度更新之前仅对一条轨迹进行采样。在进行梯度更新之前对多个轨迹进行采样绝对不会错。

该文件最重要的部分是 train 函数。我们首先初始化环境和记录器。然后,对轨迹进行采样,计算所采取行动(take actions)的对数概率以及 reward-to-go。
如您所见,我们使用一些 to_tensor 函数,这些函数将数组输出转换为 PyTorch 张量以进行快速计算。此外,我们调用 to_device 函数,它允许我们在显卡(graphics card)而不是 CPU 上进行一些计算。出于我们的目的,这些只是实现细节。
接下来,通过将行动(actions)的对数概率乘以 reward-to-go 来计算损失(目标),正如我们在上一篇博客文章中看到的那样。默认情况下,PyTorch 会累积梯度(accumulates gradients),因此我们首先调用 zero_grad 函数来重置它们。然后,我们使用 backward 函数计算损失的梯度,并使用 step 函数更新权重。
此外,此类还包含一些函数来保存和加载经过训练的模型,以及从模型中采样行动或采样确定性地(deterministically)行动。
把它们放在一起(Putting it all together)
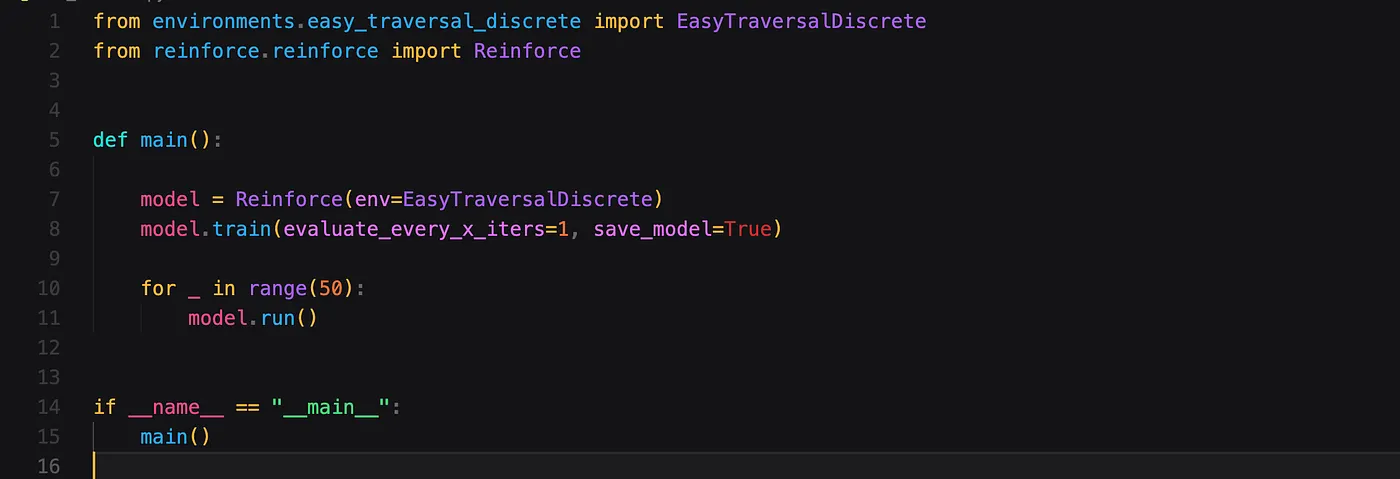
现在,我们拥有运行算法的所有要素(ingredients)。我创建了一个小的 main 函数,用于实例化我们的 Reinforce 算法并传入一个名为 EasyTraversalDiscrete 的自定义环境。使用默认的迭代次数训练模型,最后运行我们的模型!
为了完整起见,我将展示我们项目的目录结构。正如您所看到的,该项目包含一些我们尚未讨论的额外文件,现在您可以将它们视为未来教程的预告片。
总结(Conclusion)
如果您一路走到这里,那么恭喜您,已经实现了您的第一个强化学习算法,并且可能已经做好了自己研究以探索更多方法和算法的准备。
本教程的最后部分可能不太容易理解,我专门包含了图片,这样您也会思考我们在代码中做什么,而不是盲目地复制代码。如果您有任何疑问,请随时发表评论或与我联系。
最后,该项目中的文件以这样的方式排序,以便它们也允许将代码扩展到其他算法。不过,现在就这样了,感谢您关注第一个系列,我们下一个系列再见!


