译注:强化学习简介(第 3 部分)
- 说明
- Reinforcement Learning: An introduction (Part 3/4)
- REINFORCE 算法(The REINFORCE Algorithm)
- 伪代码(Pseudo-code)
- 信用分配问题(The Credit Assignment Problem)
- On-policy vs. Off-policy RL(强化学习 On-policy 比拼 Off-policy)
- 策略梯度基线(Policy Gradient Baselines)
- 结论(Conclusion)
说明
本文是对 Cédric Vandelaer 强化学习简介(Reinforcement Learning: An introduction)系列译注。仅供学习交流之用!
原文包含 4 部分,此是第 3 部分。
原文链接:Reinforcement Learning: An introduction (Part 3/4)
原文作者:Cédric Vandelaer
Reinforcement Learning: An introduction (Part 3/4)
欢迎回到强化学习(Reinforcement Learning,RL)简介系列第 3 部分。

在第 2 部分中,我们解释了一些强化学习的基本概念。今天我们将使用这些概念来讨论强化学习的算法:REINFORCE 算法。 REINFORCE 在概念上很简单,但它为您提供了理解和实现更高级算法的坚实基础。具体来说,REINFORCE 是 策略梯度(Policy Gradient) 算法系列的一部分。
译注: REINFORCE 是 'REward Increment Non-negative Factor times Offset Reinforcement times Characteristic Eligibility 的缩写。
Fun Fact: REINFROCE is an acronym for " 'RE’ward 'I’ncrement 'N’on-negative 'F’actor times 'O’ffset 'R’einforcement times 'C’haracteristic 'E’ligibility. => Info from: gymnasium tutorials.
此篇博客依次讨论如下内容:
- The REINFORCE Algorithm(REINFORCE 算法)
- Pseudo-code(伪代码)
- The Credit Assignment Problem(信用分配问题)
- On-policy vs. Off-policy RL(强化学习 On-policy 比拼 Off-policy)
- Policy Gradient Baselines(策略梯度基线)
REINFORCE 算法(The REINFORCE Algorithm)
REINFORCE 是一种策略梯度算法。策略是定义智能体行为的函数。我们将策略定义为一个参数化函数:
这里的 是我们参数为 的策略。该策略将状态 作为输入,并生成动作分布作为输出(智能体执行特定动作 的概率)。在这个案例,我们讨论的是随机策略(stochastic policy),因为策略输出概率(probabilities)而不是直接输出行动(action)。
策略梯度算法(Policy gradient algorithms)试图通过改变策略函数(policy function)的参数(parameters)来直接改进策略,使得策略产生更好的结果。
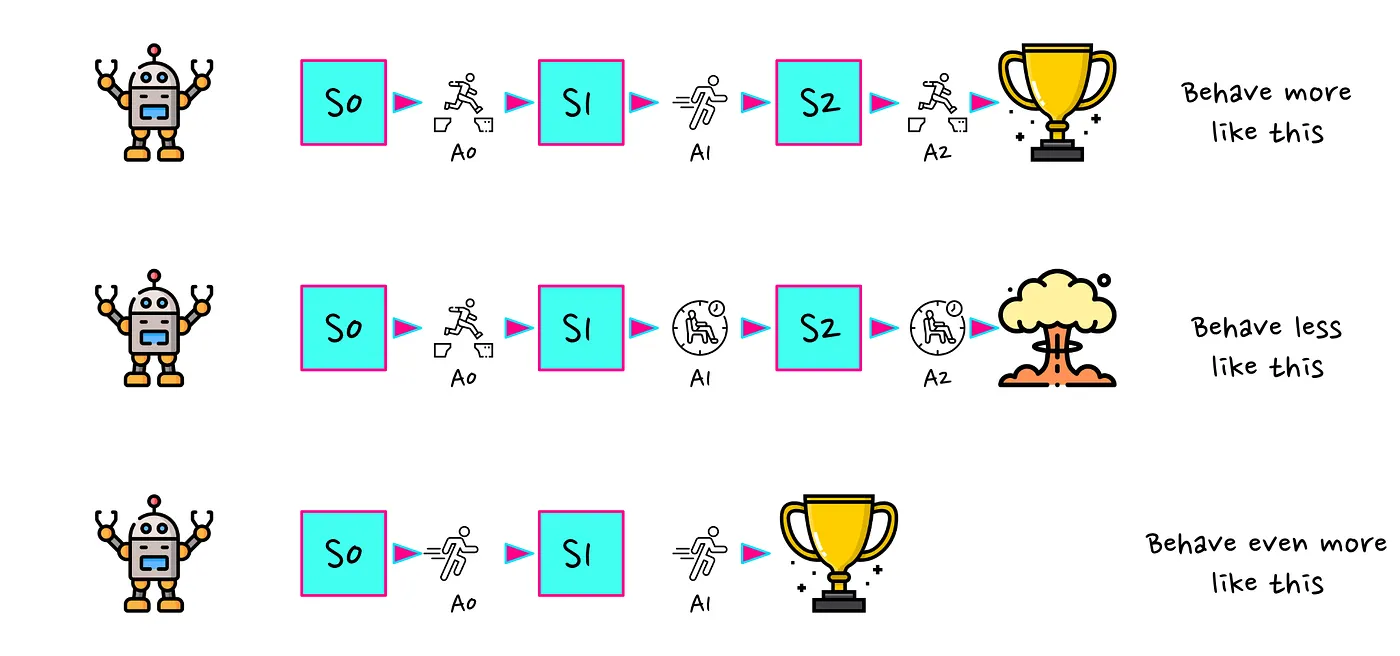
这也是 REINFORCE 算法正在做的事情。其主要思想是:从随机策略开始(因此我们的智能体将采取随机操作)。接下来,我们让智能体根据这个策略在环境中运行。这将产生一个轨迹(智能体采取的一系列状态和行动)。如果智能体在此轨迹中获得高奖励,我们将更新我们的策略,以便策略产生的轨迹下次更有可能发生。反之亦然,如果我们的智能体表现不佳,我们将降低所选轨迹被选择的可能性。一直重复这个过程,直到我们(希望)获得好的策略。
伪代码(Pseudo-code)
我们刚刚描述的过程如下所示:
1 | initialise policy P with random parameters θ |
让我们把这个伪代码分解成更容易理解的部分。
1 | initialise policy P with parameters θ |
我们将首先初始化策略 和参数 。
在本系列的第二部分中,提到通过神经网络表示策略。然而,这不是必须的,对于策略梯度算法,我们可以使用任何可微学习方法(differentiable learning method)。简而言之,可微学习方法意味着我们知道一种计算如何更新策略参数的方法。在这篇博文中,我仍然会选择神经网络。
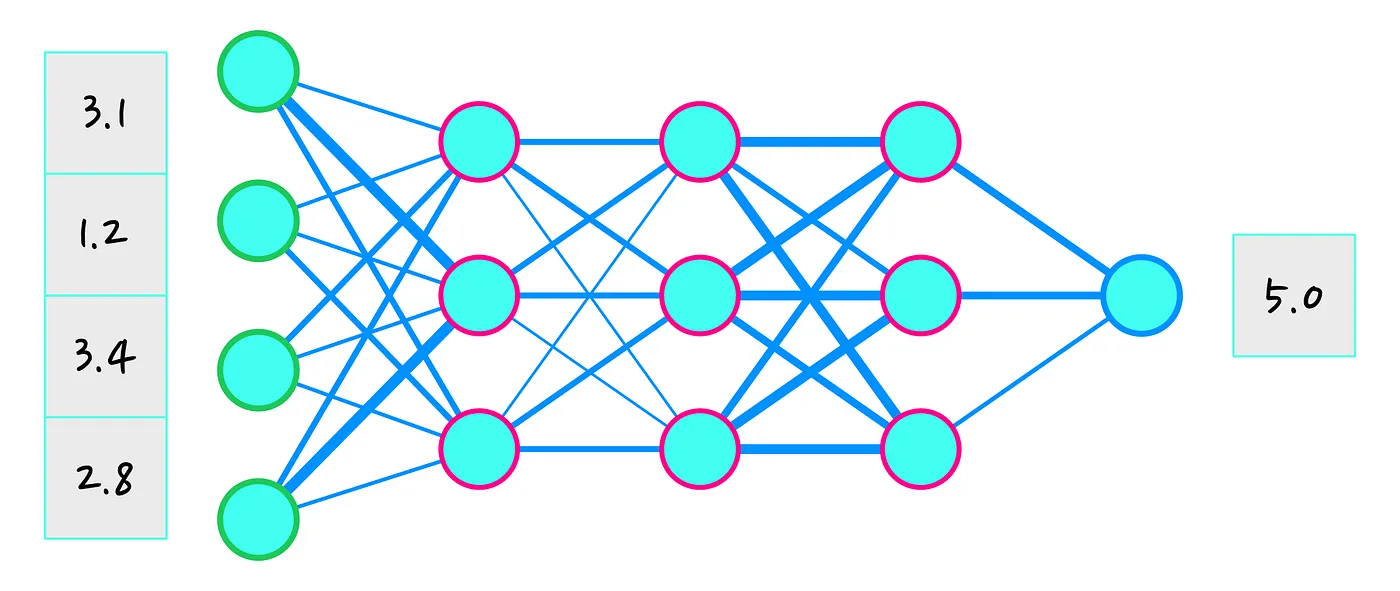
神经网络在第一层接受一些输入,并在最后产生一些输出。我们的参数是神经元之间的连接(权重)。它们通过增强(strengthening)或减弱(weakening)上一层产生的信号来影响输出。开始时,这些连接是随机的。所以我们的策略初始时会给随机的行动。
1 | repeat until agent performs well: |
我们暂时可以忽略伪代码中的下一行。这只是意味着重复接下来的步骤,直到我们对代理的表现感到满意为止。
1 | generate trajectory τ (s₀, a₀, s₁, a₁, s₂, ...) with reward R |
这里我们生成一条轨迹 。这意味着我们现在将让智能体与环境交互。从起始状态(state) (由环境决定)开始,然后让智能体(agent)根据该时间点参数(parameters)为 的策略(policy) 进行操作。因此,我们将采用状态 作为神经网络(我们的策略)的输入,并从中获取行动(actions)的分布。然后通过从该分布中采样来选择一个行动(action) 。执行所选的行动(action)并到达新的状态(state) 。重复这个过程,直到达到最终状态,即回合(episode)的结束(由环境决定)。这就是我们得到轨迹 的方法。
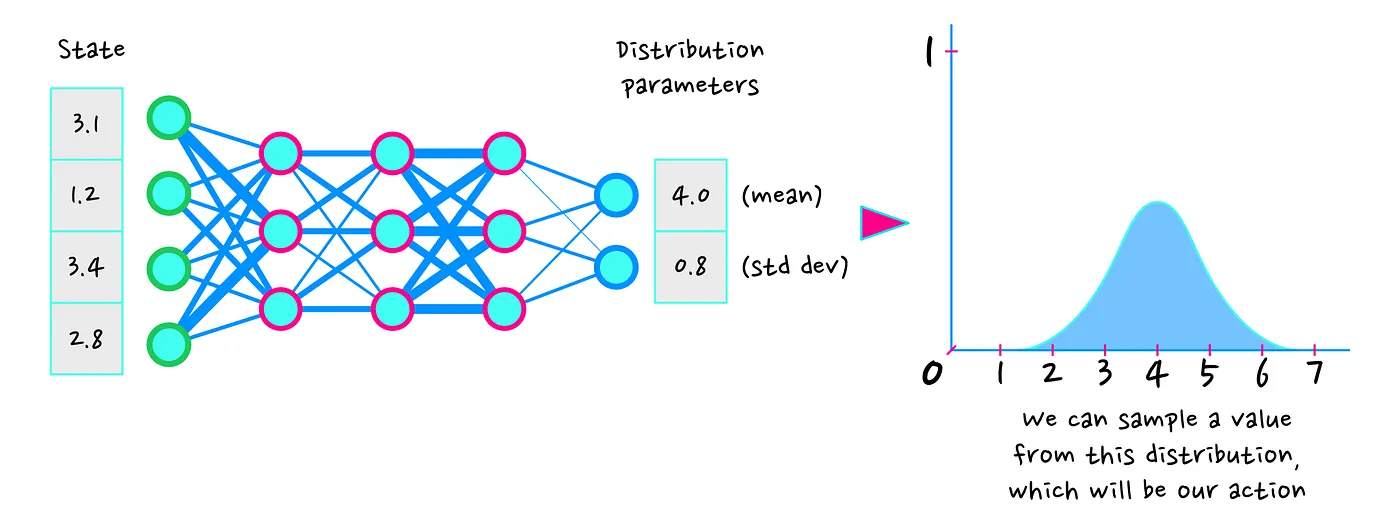
如果您想知道如何从神经网络获得分布,请考虑许多分布仅由几个参数定义。以高斯(正态)分布为例,正态分布由平均值(mean)和标准差(standard deviation)定义。网络可以将状态作为输入并产生两个标量(平均值和标准差)作为输出。由此可以构建分布并从中采样一个动作。
请注意,我们不一定需要使神经网络同时输出平均值和标准差。常见的做法是假设一定的标准差并让神经网络仅预测平均值。
1 | for each state sₜ in trajectory τ: |
让我们一起看看接下来的两行。第一行只是意味着为轨迹的每个时间步重复该过程。接下来的一行引入了一个新概念,即reward-to-go”。reward-to-go 是指从某个状态(state)起开始的轨迹(trajectory)中获得的奖励。
译注:注意,这里的 reward-to-go 指的是在一个包含多个 state 的 trajectory 所获得的 rewards,是累积 reward。

例如,对于轨迹的第一个状态,这说明了轨迹的总奖励(total reward)。然而,我们也会考虑折扣因子(discount factor)。折扣因子使我们对未来奖励(future rewards)的重视程度低于对即时奖励(immediate rewards)的重视程度。这里,我们为 reward-to-go 提供了以下公式:
是折扣因子(discount factor),其值在 到 之间。 是时间步 的奖励。如果非常关心未来的奖励,可以将 的值设置为 。如果主要关心即时奖励,可以给它一个较低的值,比如 。
1 | calculate policy gradient L(θ) using G |
我们已经到了策略梯度(policy gradient)。您可能想知道梯度到底是个什么东西。**梯度是一种确定参数变化如何影响函数结果的数学方法。**如果您碰巧还记得高中的导数(derivative),那么这个想法是有些相同。除了我们将处理具有多个变量的函数之外。
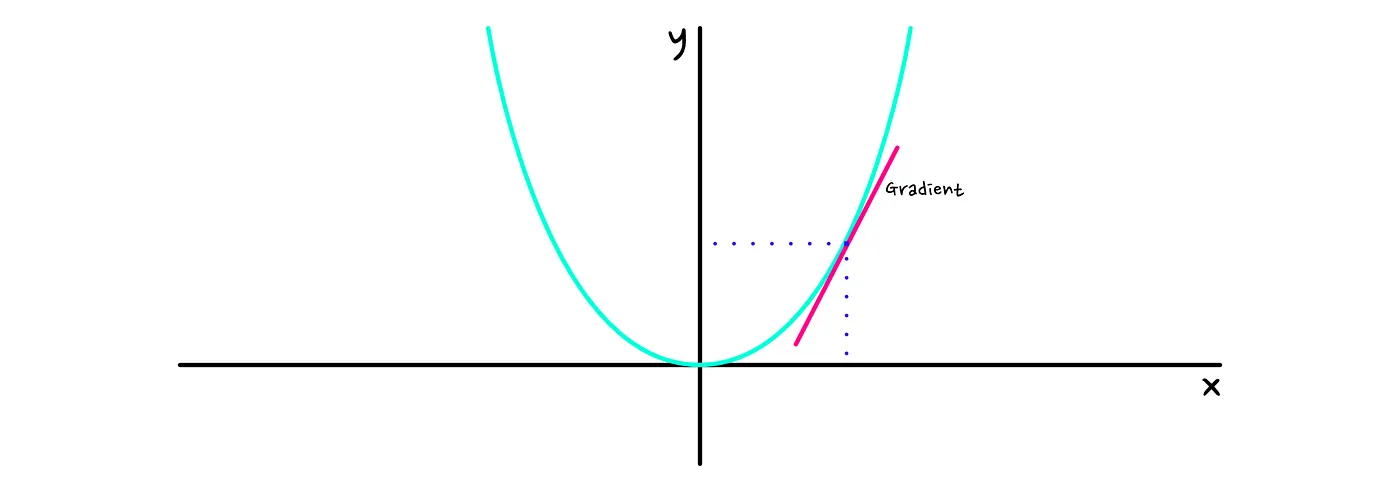
我们想知道应该如何更新策略 的参数 ,以便具有与其相关的高 reward
-to-go 的轨迹更有可能发生,反之亦然。
你可以将策略、神经网络想象成一台有很多旋钮需要转动的大机器。我们想要计算应该如何转动这些旋钮,以使良好的轨迹更有可能发生。梯度是告诉我们应该如何转动这些旋钮的方法。
假设我们有一个告诉我们对于给定的策略可以期望什么回报(轨迹的总奖励)的函数 :
是轨迹(trajectory) 的回报(return)。该公式告诉我们,对于政策 ,预期回报(expected return)等于给定策略 时我们期望随行(follow)的轨迹的回报(return)。我们想要最大化 的值。所以我们将尝试计算 的梯度(gradient)。这里引出了下一个公式:
这里的 符号代表梯度(gradient)。它将告诉我们如何改变 的值来增加 的值。具体来说,梯度为我们提供了一组值( 中的每一个参数)。**您可以将这些值视为指向函数 结果最高的地方的一个方向(direction)。**如果我们将这些值添加到参数 中, 的值将最大程度地增加。
不幸的是,我们不能直接用上面的公式进行任何微积分(calculus)。我们将推导出一个等效的公式,以用来在实际使用时计算。完整的数学推导会让我们有点偏离话题了,但如果您对如何推导梯度感兴趣,请您阅读 OpenAI 的这个网页:Deriving the simplest policy gradient(推导最简单的策略梯度)。
我们的策略梯度的计算如下所示:
这个公式告诉我们如何计算 的梯度。右侧开头的是期望符号(Expectation-symbol) 。期望表示我们在遵循策略 时期望获得的轨迹 (如果你愿意的话,也可以是平均轨迹)。我们无法准确计算哪个轨迹是预期轨迹,因为这需要我们计算策略的所有可能轨迹。幸运的是,我们可以对一个或多个轨迹进行采样,并且这些轨迹应该接近预期轨迹。
采样后,我们应用括号内的公式 来表示策略 给定状态 下行动 的概率。然而,我们将使用该概率的对数(log of this probability)。取对数将使梯度计算过程更加稳定(stable),因为它允许我们对每个时间步的梯度求和,而不必将它们相乘。乘法运算可能会使梯度变得非常小或非常大,从而导致数值不稳定(instability)。您可以查看推导链接以了解获取对数(log)实际上是等效的。
最后,我们计算这个函数的梯度,给我们一个方向。我们将这个方向乘以 ,即 reward-to-go 。如果 很高,我们就沿着梯度的方向前进,使动作 更有可能发生。如果 较低,我们朝相反方向迈进(或者我们采取与 高的轨迹相比,相对较小的步长)。
梯度计算通常由我们使用的编程库(例如 Tensorflow 或 Pytorch)负责。如果您对如何手动计算离散动作空间(discrete action spaces)和连续动作空间(continuous action spaces)的策略梯度感兴趣,那么我推荐您这篇优秀的文章,该文章对数学进行了更深入的研究:RL Policy Gradients explained by Jonathan Hui(强化学习策略梯度说明,Jonathan Hui)
1 | update policy parameters θ using L(θ) |
到了算法的最后一行。在此步骤中,我们将使用刚刚计算的梯度来更新神经网络的权重(策略,the policy)。
我们的梯度是一个向量(vector),包含每个参数 的值。所以现在我们将通过以下方式简单地更新我们的权重:
如果您仍然对神经网络的工作原理以及我们如何更新这些权重有些困惑,我推荐这个解释 反向传播(backpropagation) 的视频。反向传播是计算和应用这些梯度的算法。
请注意,视频中旁白谈到了损失函数(loss function)。严格来说,我们没有计算损失函数的梯度,尽管计算有些相似。我们正在计算策略梯度。损失函数(如视频中所示)是直接指示神经网络在学习数据集方面表现如何的。损失函数的值较高意味着您的网络犯了很多错误。这对于策略梯度来说并不成立,没有迹象表明我们的智能体有多成功。另一个区别是,我们并不是试图最小化我们的策略梯度,而是试图最大化它(梯度上升而不是下降)。实现这一目标的一个简单技巧是对策略梯度的负值执行梯度下降。
信用分配问题(The Credit Assignment Problem)
您可能会看到上面的解释并想知道“REINFORCE 如何从不好的行动(bad actions)中过滤出好的行动(good actions)?”。我们的智能体可能会采取非常糟糕的行动,但最终仍然得到相对较好的分数。在这种情况下,我们会强化这种行为(reinforce that behaviour),使不好的行动(bad action)更有可能发生。反之亦然,我们的智能体可能会采取非常好的行动(very good action),但并没有带来好的分数。在这种情况下,导致好的行动(good action)的行为(behaviour)就会受到阻碍。
我们描述的问题是所谓的信用分配问题: 我们的算法无法确定整个轨迹过程中哪些行动(actions)是好的行动(good actions),哪些是不好的行动(bad actions)。 这是否意味着 REINFORCE 不起作用?不是的。将会发生的情况是,在良好的轨迹(good trajectory)中,平均而言,好的行动应该多于坏的行动。对于不良轨迹(bad trajectory),反之亦然。因此,在我们经过足够的迭代(iterations)之后,模型将开始对这些轨迹进行平均,并最终对好的行动(good actions)产生偏差(bias)。
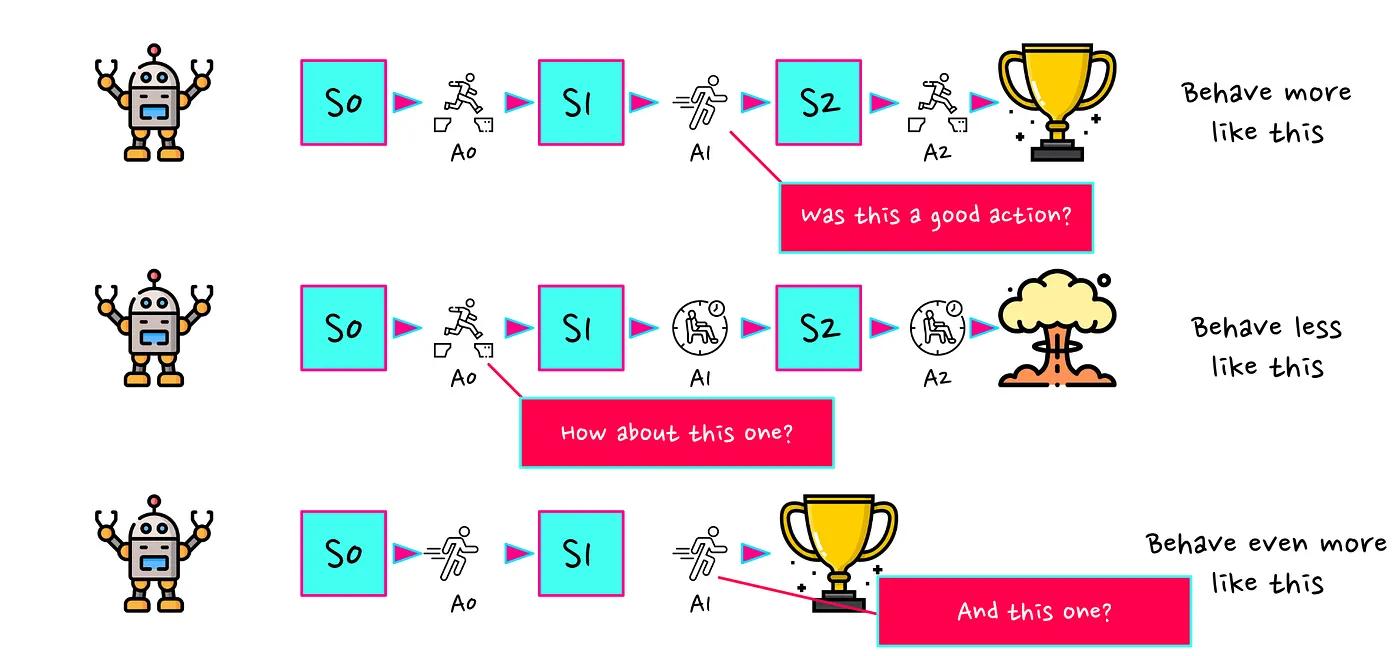
信用分配问题的一个后果是我们的算法样本效率更低(sample-inefficient)。 我们需要评估更多的轨迹,以开始从好的行动中过滤掉不好的行动。有很多试图专门解决这个问题研究。例如,研究人员尝试使用一个单独的神经网络来学习从轨迹中的行动(actins)推断即时奖励(infer immediate rewards )。Link to paper(论文链接)
On-policy vs. Off-policy RL(强化学习 On-policy 比拼 Off-policy)
REINFORCE 算法的另一个特点是它是一种 on-policy 算法。 On-policy 指策略根据从相同策略收集的经验(experience)进行更新。 这正是 REINFORCE 中发生的情况。每次迭代,我们的智能体都会根据最新版本的策略进行操作。然后,我们根据从这些交互(interactions)中学到的来更新策略。
事实并非如此。Off-policy 强化学习算法可以根据从之前或其他策略中学到的来更新其策略。请看下图示例。
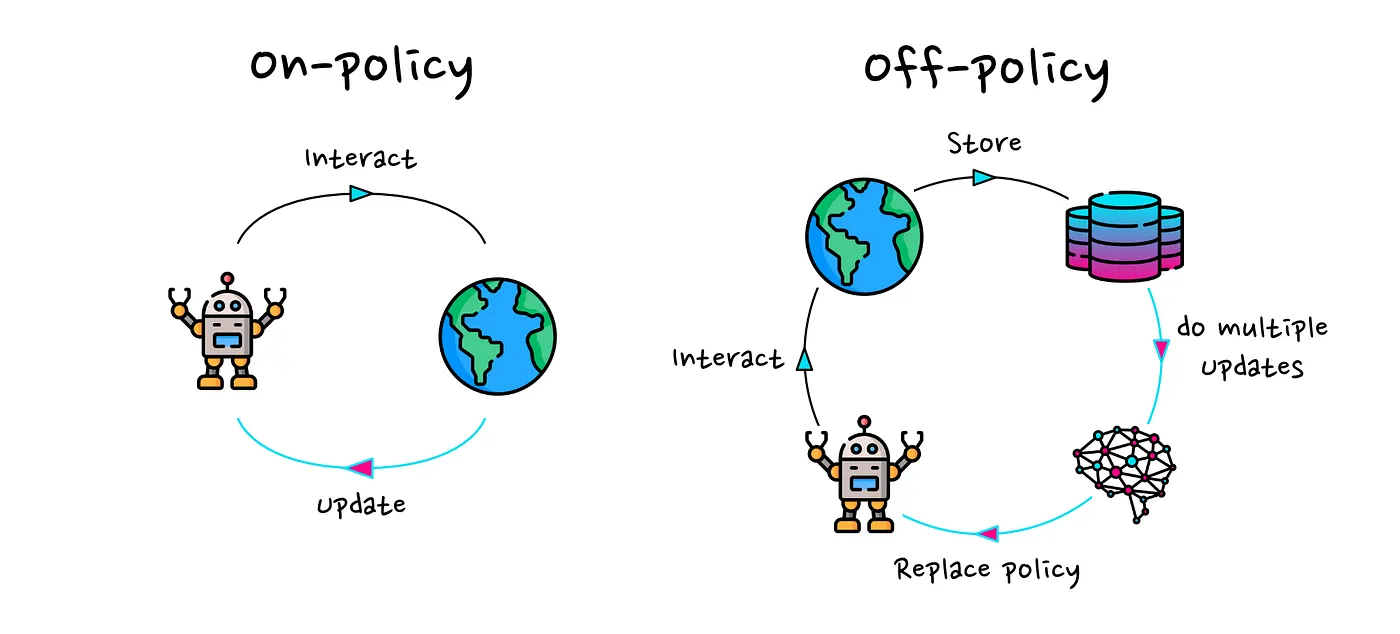
在 on-policy 情况下,智能体不断与环境交互,一旦收集到新的经验(experience),策略就会更新,智能体也会做出相应的行为(the agent behaves accordingly)。
在 off-policy 的情况下,我们有一个智能体(或多个智能体)根据策略行事,我们将此策略称为行为策略(behaviour-policy)。他们收集的经验(experience)被保存在缓冲区(buffer)中。然后,我们利用收集到的经验(experience)来训练一个行动选择策略(policy for action selection)。因此,在这种情况下,我们的缓冲区(buffer)可以包含旧版本策略的经验(experience),甚至是完全不同的策略。我们刚刚描述的方法经常出现在 Q-学习(Q-learning)算法中。
因为智能体与环境进行可能更少的交互,因此 Off-policy 方法有可能更加有效地采样(sample-effective)。他们也不太容易陷入局部最小值。其原因是,在 on-policy 情况下,智能体可能对某种行为(behaviour)产生了强烈地偏差(bias),以至于与这种行为的微小偏差(deviations)不再足以发现新的(和改进的)策略(strategies)。这就是为什么更复杂的(sophisticated) on-policy 方法往往试图纳入(incorporate)一种机制以促进(encourages)智能体进行更多的探索(exploration)。
在强化学习 off-policy 最极端(extreme)的情况下,我们只让智能体与环境交互一次。因此,迄今为止,我们收集的经验(experience)类似于示例交互的有限数据集。这就是所谓的 offline RL(离线强化学习),是近几年研究强化学习比较突出(prominent)的方向之一。offline RL 之所以受欢迎,仅仅是因为它在现实世界中的实用性(practicality)和适用性(applicability)。然而,Offline RL 是非常困难,因为收集训练数据的智能体按照未知的策略行事。如果您想了解有关 offline RL 的更多信息,请查看 Sergey Levine 等人所做的令人难以置信的工作:Offline RL paper。
策略梯度基线(Policy Gradient Baselines)
在结束博客的这一部分之前,我们还需要谈一件事。让你看看,我们可以用一种更微妙(subtle)的方式改进我们的 REINFORCE 算法版本。
在我们当前版本的算法中,轨迹与轨迹给我们的回报(return)(累积奖励,cumulative reward)或多或少成比例的方式应用梯度。我们构造轨迹的多少都是相对的。从数学上来讲,梯度的大小完全取决于轨迹的返回。
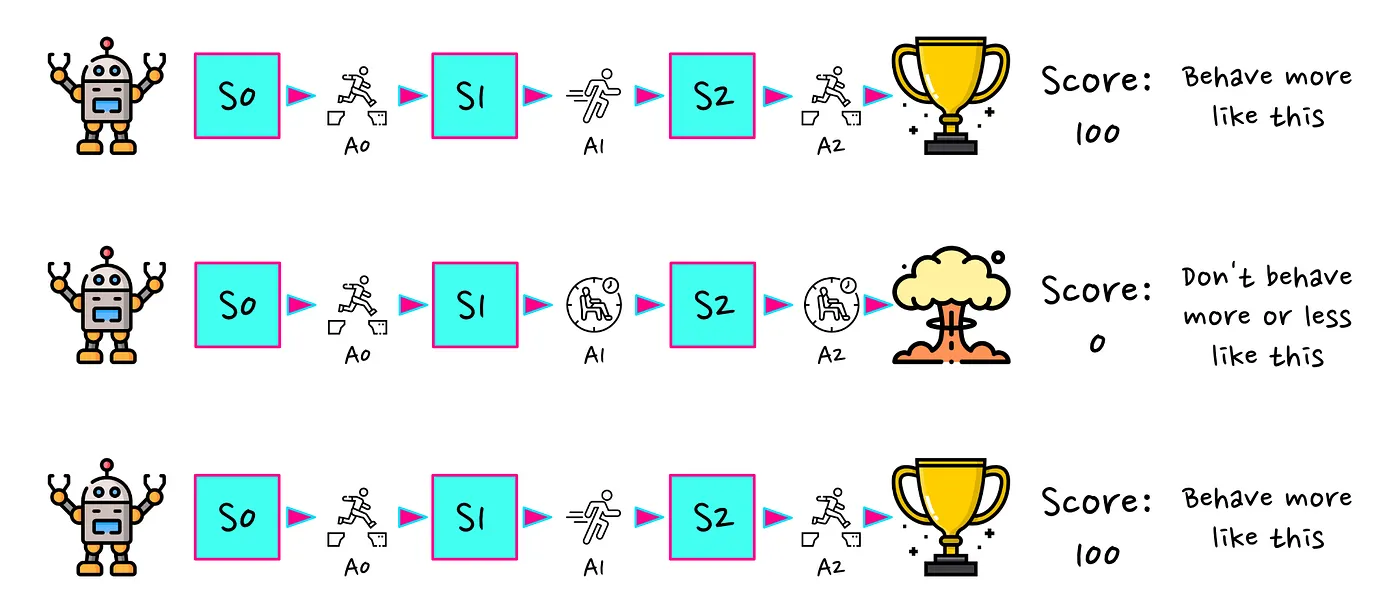
在上图中,您可以看到我们得到三个分数: 、 和 。所以我们的算法要做的是相应地更新策略。乍一听这似乎很理想,但实际上并非如此。因为最后一条轨迹与第一个轨迹相似,我们再次使其更有可能。一段时间后,这可能会导致行为(behaviour)发生巨大变化,从而可能对游戏的平均结果产生不利影响。如果我们在特定方向上更新过多的策略参数,它们可能会开始表现出不必要的行为(unwanted behaviours)。
那么我们能做些什么呢?直观上,我们希望梯度不仅根据分数进行更新,而且当智能体比预期做得更好或更差时也希望更新它。我们可以通过引入基线(baseline)来实现。
这里显示的公式与我们的策略梯度完全相同,只有一个区别:我们从 reward-to-go 中减去 。请记住,价值函数(value function)是估计(estimator)处于特定状态并根据特定策略行为的价值的。因此,在这种情况下, 是一个很好的基线,因为通过从 中减去 ,我们现在只会更新我们的策略“如果我们做得比预期更好或更差”。在实践中,我们不知道 的确切值。因此,通常在算法过程中,另外训练一个估计 的神经网络。
那么为什么基线可以实际上改善训练过程呢?从数学上来说,添加适当的基线将减少样本的方差(variance)。简单来说,我们的策略会有更清晰的学习信号,这会让训练更快、更稳定。在后面的文章中我们将更多地讨论基线。
结论(Conclusion)
在今天的帖子中我们再次探讨了很多话题。恭喜您已经走到这一步了!您现在应该对基本策略梯度算法有固化的了解。此外,这篇文章将帮助您做好在下一篇文章中亲自动手的准备。如果这篇文章对您来说非常理论化,或者您通过代码学习得更快,那么请继续阅读本介绍系列的最后一篇文章!


