译注:强化学习简介(第 2 部分)
- 说明
- Reinforcement Learning: An introduction (Part 2/4)
- 强化学习框架(The RL framework)
- 状态(States)
- 行动(Actions)
- 奖励函数(Reward function)
- 环境动态(Environment dynamics)
- 策略(Policies)
- 轨迹与回报(Trajectories and returns)
- 价值函数和Q-函数(Value function and Q-function)
- 结论(Conclusion)
说明
本文是对 Cédric Vandelaer 强化学习简介(Reinforcement Learning: An introduction)系列译注。仅供学习交流之用!
原文包含 4 部分,此是第 2 部分。
原文链接:Reinforcement Learning: An introduction (Part 2/4)
原文作者:Cédric Vandelaer
Reinforcement Learning: An introduction (Part 2/4)
欢迎回到强化学习(Reinforcement Learning,RL)简介系列第 2 部分。

在第 1 部分中,我们描述了强化学习是什么、可以用它做什么以及强化学习的一些挑战。这一次,我们将解释 强化学习的一些主要概念并介绍一些术语和符号。这对于我们将在下一部分讨论简单的强化学习算法很有用。
具体我们将讨论:
- States(状态)
- Actions(行动)
- Reward functions(奖励函数)
- Environment dynamics (Markov Decision Processes)(环境动态(马尔可夫决策过程))
- Policies(策略)
- Trajectories and return(轨迹和回报)
- Value function & Q-function(价值函数 和 Q-函数)
与往常一样,如果您已经熟悉内容,请随时移至下一部分。
强化学习框架(The RL framework)
让我们先快速回顾一下。强化学习框架涉及一个尝试在特定环境(environment)中解决任务的智能体(agent)。在每个时间步(timestep) t,智能体需要选择一个动作(action) a。在此操作之后,它可能会收到奖励(reward) r,并且我们会对其状态(state) s 进行新的观察(observation)。新状态既可以由智能体的行为决定,也可以由智能体运行的环境决定。在强化学习中,我们希望最大化未来的累积奖励。
为了便于解释,我们将使用乒乓球游戏来进一步解释这些概念。
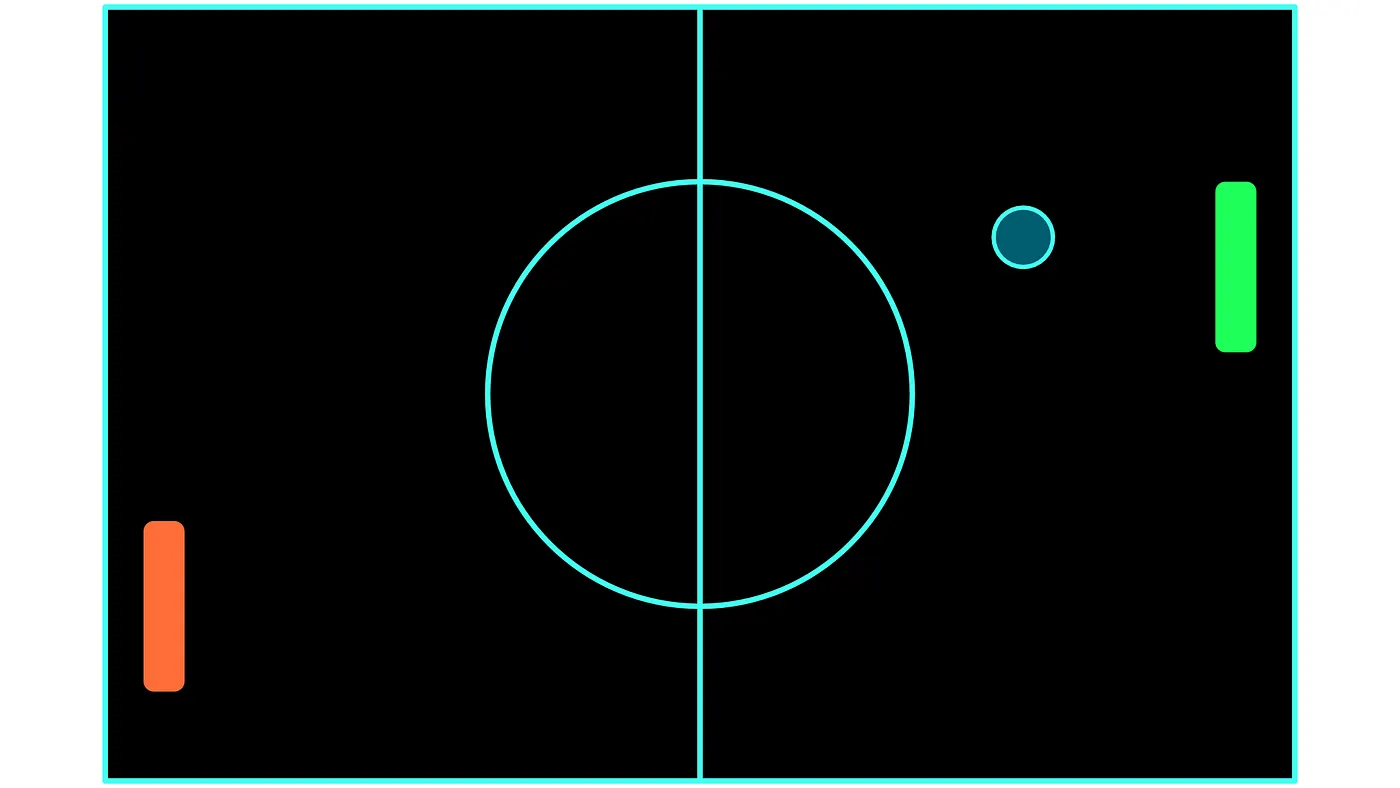
乒乓球是一种很容易解释的游戏:有两名玩家,由上图中的绿色和红色球拍表示。在我们的示例中,我们将操作绿色球拍的玩家视为我们的智能体。乒乓球的目标是将球弹回,越过其他球员的球拍。当任何一名球员设法将球弹过另一名球员时,他就得一分,并且球再次开始从球场中心移动。得分最高的玩家获胜。
当我们想要训练 RL 代理打乒乓球时,RL 框架的不同术语如何应用?
状态(States)
让我们从状态开始。状态通常是向量(vector)、矩阵(matrix)或其他张量(tensor)。如果您不熟悉这些术语,请不要担心,它们本质上是组织数字的各种方式。您可以查看下图作为示例。
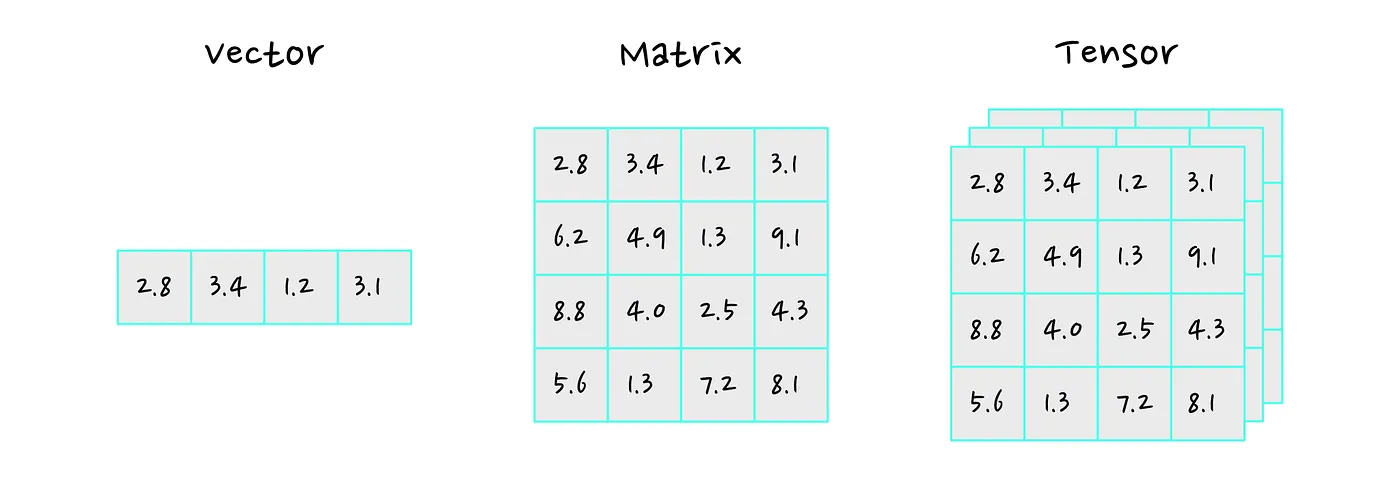
状态应该描述我们需要的相关信息,以便决定在时间步(timestep) 采取哪些行动。我们将时间步 处的状态表示为 。
就乒乓球样例而言,状态的良好描述可以是一个向量(数字数组),其中包含玩家球拍的位置、球的位置和球的角速度。这足以让我们的智能体决定最好将球拍向上还是向下移动。因为从这些信息中它可以检查自己的位置、球的位置以及球的移动方向。
请注意,仅对球和玩家的位置进行编码是不够的,因为我们还需要一些指示球移动方向的信息。
另一种选择是直接使用游戏的帧/像素来表示状态。该状态是表示像素的光强度/颜色的矩阵或张量。这对于人工智能算法来说会更难学习,但无疑是可能的。会更难,因为现在它不仅需要学习如何玩游戏,还需要学习如何从这些像素中提取相关信息。例如,它需要了解中间的蓝色像素代表一个球,并且需要了解该球的位置与解决该问题相关。
注意:我们也遇到了与使用状态向量时遇到的相同问题,即:一张静态图像不足以显示球正在朝哪个方向移动。作为解决方案,状态通常表示为最后几帧的堆栈(the state is often represented as a stack of the last few frames)。
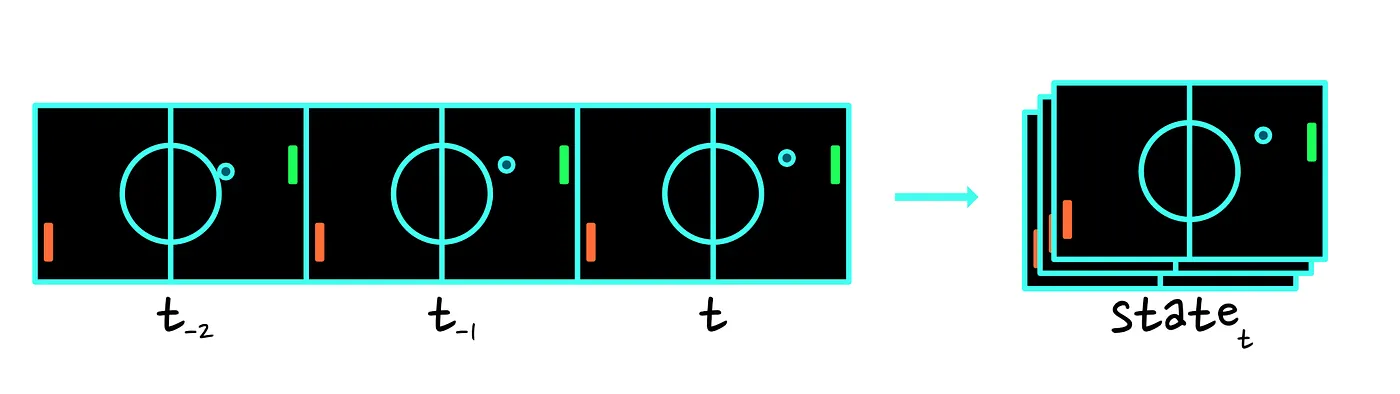
最后一点,尽管我们使用 “状态(state)” 一词,但 “观察(observation)” 一词会更合适。不同之处在于,状态被假定为对世界状态的完整描述,而术语“观察”是指对状态的(可能是部分的)观察。在我们的研究用途中,可互换使用这些术语。
行动(Actions)
在乒乓球游戏中,我们希望我们的智能体能够上下移动球拍。
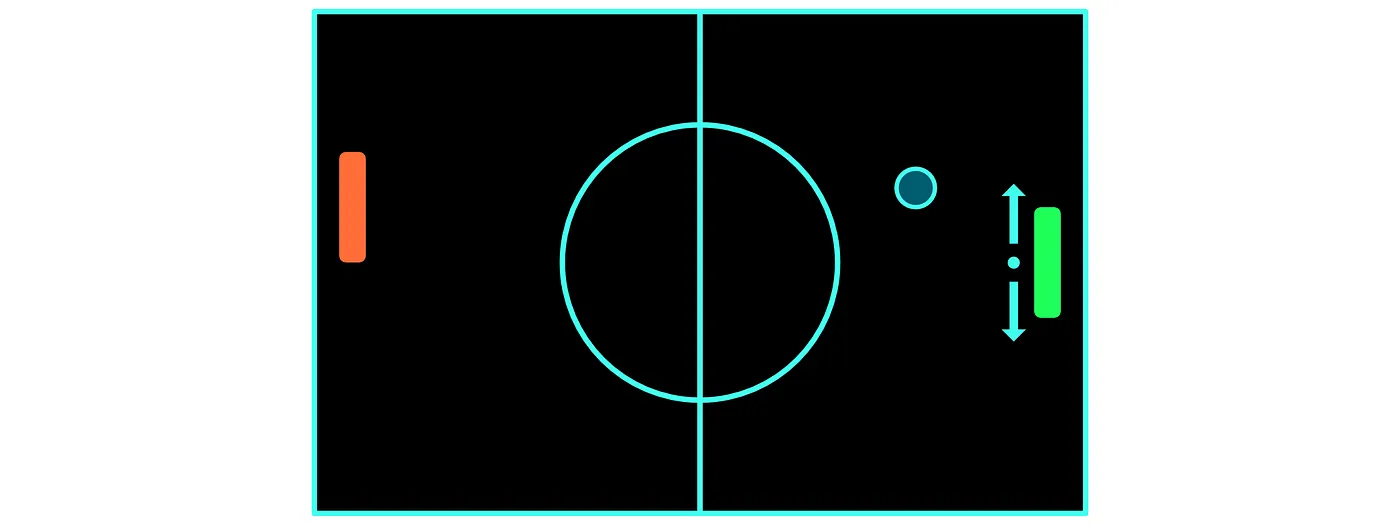
表示此动作的方法有很多种,但首先,一般来说,强化学习中的行为有一个重要的区别。我们将区分 离散动作空间(discrete action spaces) 和 连续动作空间(continuous action spaces)。
在离散动作空间的情况下,我们的动作是离散(discrete)的,这是说它们只能采用一组特定的值。例如,在乒乓球游戏中,我们可以将我们的动作定义为“向上”、“向下”和“不动”。这意味着我们的球拍可以在每个时间步向上、向下移动或静止不动,但只能移动预定的量。例如,向上移动可能意味着我们每次向上移动 10 个像素。

为了表示这三个动作,我们可以使用向量(数字行),其中向量的每个维度(列)指示要采取的行动。通常,向量中的值仍然是连续的,并表示智能体应采取的操作的“分类分布(a categorical distribution)”。您现在可以忽略这一点,只需将其视为“向量中数字为 1 的维度,就是我们的智能体将采取的行动”。

在连续动作空间的情况下,我们的动作是连续(continuous)的,这意味着它们可以呈现任何值。因此,如果我们看看乒乓球游戏,现在我们的动作可能不仅仅代表球拍向上或向下移动,而且我们还可以指定球拍应该向上或向下移动多少。在这种情况下,具有单一维度(标量,a scalar)的向量就足够了。标量可以具有正值(表示向上移动)、0(表示不移动)和负值(表示向下移动)。
奖励函数(Reward function)
奖励函数告诉我们在每次行动之后,智能体因采取该行动而获得了多少奖励。或者更精确地说:奖励函数在每个时间步 都将状态 和行为 作为输入,并输出奖励 。奖励 是一个表示智能体表现如何的标量(数字)。
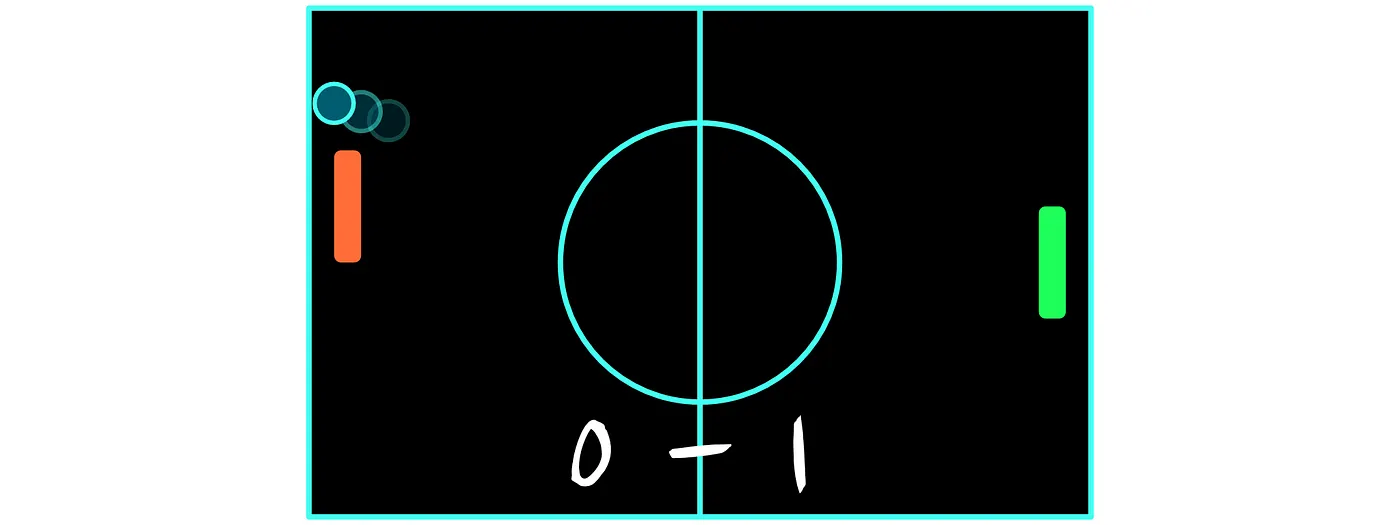
在乒乓球游戏中,我们可以选择智能体每次使球成功越过其他球员的球拍时奖励 1,当没有人得分时奖励 0,当他错过球导致对手得分时奖励 -1。
形式上,奖励函数可以记作:
这里的 代表一组状态(states), 是一组动作, 是实数集。
您应该在选择如何定义智能体获得的奖励时要小心,因为这可能会严重影响智能体的行为。例如,它可以产生不可预见的后果,或者您的智能体看到的奖励太少(稀疏奖励问题),可能根本无法学习任何东西。
环境动态(Environment dynamics)
环境动态回答以下问题:给定状态和行动,下一个状态将是什么? 通常,我们不需要自己对这些进行环境动态建模。强化学习算法需要自行解决这些问题。更重要的是,许多问题的环境动态是未知的。
尽管如此,我们将简要讨论环境动态的想法,因为我们能够将强化学习应用于问题的唯一要求是,从理论上讲,我们能够将问题定义为马尔可夫决策过程(MDP)。
马尔可夫 —— 你问什么?您会看到这个词出现在大量的强化学习文献中,原因是 MDP 是一种形式化问题表述的方式。他们还将帮助解释我们以后将要使用的一些算法。让我们谈一谈 MDP。
马尔可夫决策过程(Markov Decision Process)
马尔可夫决策过程是具有马尔可夫属性(Markov property)的离散时间(discrete-time)随机(stochastic)控制过程。这真是满口胡话(This is a mouth-full),它并非那么复杂(but it’s not so complicated)。下边让我们解剖一下。
我们正在描述一个拥有一组状态的过程。这些是在解决问题的过程中智能体可以处于的状态。该过程是在离散时间建模的,这大致意味着发生的一切都表示为单独的时间点。换句话说,您不能处于“在……之间”两个状态,要么处于一个状态,要么不是。然后,一个时间点由一个数字表示,下一个时间点是该数字+1。
我们还定义了状态转换分布(transition distribution):
转换(transition)指着从一个状态到另一个状态。这个公式告诉我们,在当前的状态 采取行动 时,进入下一个状态 的可能性。这就是我们定义的 “随机(stochastic)”,随机指我们采取行动 进行处理的概率。有时智能体可能会决定采取行动,但是由于环境,可能无法保证最终会达到其预期的状态。
最后但并非不重要的一点是,控制过程需要具有 马尔可夫属性。马尔可夫(Markov)指的是它的发明者安德烈·马尔可夫。该属性告诉我们任何下一个状态仅取决于当前状态。当一个过程具有马尔可夫性质时,下一状态不依赖于除当前状态之外的任何其他状态。因此,我们的智能体之前可能已经见过百万个状态,但确定下一个状态仍然不重要,只有当前状态才重要。
下图显示了此类过程的示例。被圆圈包围的 代表状态,而粉色圆圈代表在这些状态下可以采取的行动。代表起始状态的 是绿色的。大多数过程也有终止状态(标记过程结束的状态),但这里没有绘制它们。

例如,在时间步 处于状态 ,可以采取行动 或 。如果选择操作 ,那么有 26% 的机会在时间 时结束于状态 ,而有 74% 的机会在时间 处结束于状态 。请注意,之前访问过哪些状态对确定下一个状态并不重要。
太棒了,这就是全部内容,现在您知道马尔可夫决策过程(MDP)是什么了!乒乓球游戏的 MDP 会是什么样子?我们已经讨论了智能体的状态和行为。这些状态描述了球拍和球的位置以及球的速度。我们可以采取的行动是向上或向下移动。
在乒乓球游戏中,我们正在处理一个完全可观察(fully observed)的环境,我们可以访问该游戏中的所有信息。这并不总是正确的,有时我们的环境只能被部分观察(partially observed)。比如,想想纸牌游戏,您无法看到对手持有的牌。
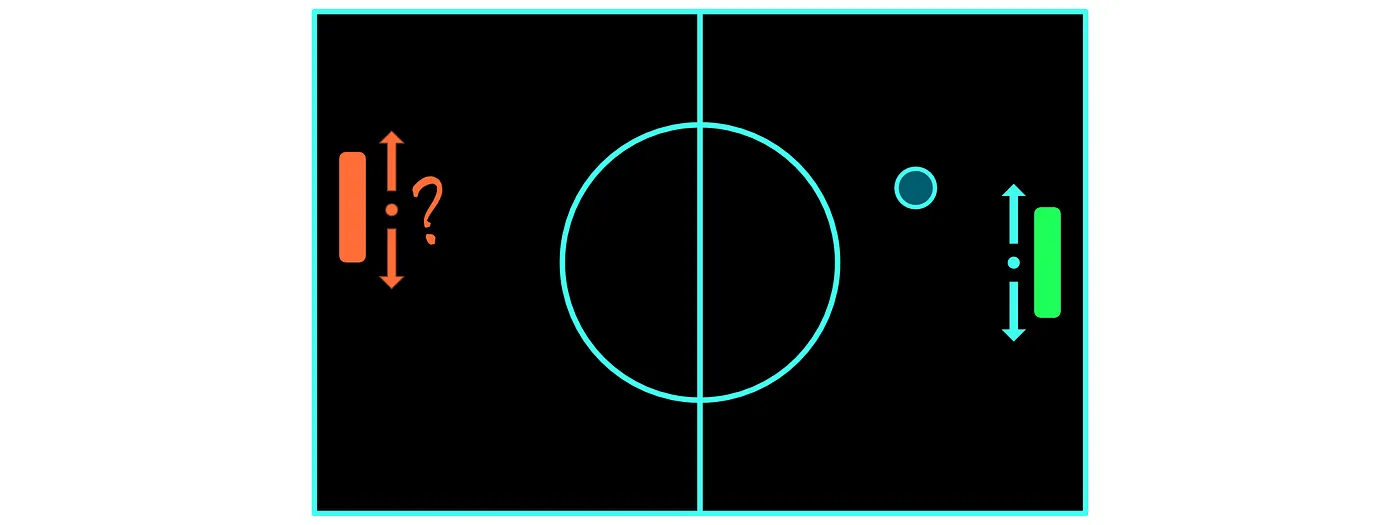
然而,正如我们正在描述的,我们的环境仍然是随机的。造成这种情况的原因主要是我们的对手。假设我们的球拍处于位置 ,而我们的对手位于位置 。尽管我们可以决定球拍如何移动,并且移动球的物理原理可能是确定性的,但对手的球拍可能会随机或概率地移动。
策略(Policies)
好吧,我们今天的文章要介绍很多术语,接下来是测策略。当谈论测策略时,我们指的是智能体的“行为(behaviour)”。给定一个状态,智能体下一步应该采取什么行动?这是算法的关键。
类似与我们对行动所做的,我们将区分确定性策略(deterministic policies)和随机策略(stochastic policies)。确定性策略可表示为:
此公式中, 是时间步 时的行动, 是时间步 时的状态, 是参数为 的策略函数。您可以简单地将这个公式视为一个数学函数,它接收一些输入(状态),然后输出智能体要采取的相应行动。参数 影响函数的输出,因此我们希望更改这些参数,以便智能体以最佳行为去最优的解决问题。我们将在下一篇博客文章中看到如何做到这一点,现在不用担心它们。
另一方面,随机策略看起来像这样:
此公式与确定性策略非常相似。 是时间步 时的行动, 是时间步 时的状态, 是参数为 的策略函数。使用 表示随机策略是一种惯例。与确定性策略的区别在于,我们以一定的概率选择行动 ,但很可能在下一次处于类似状态时,我们会选择不同的动作。
神经网络(Neural networks)
您可能会想,这些策略看起来不错,但是我们使用什么函数来对它们进行建模呢?
在实践中,我们经常使用神经网络(neural network,NN)来实现这些功能。记住,我们毕竟正在尝试创建一个自学系统(self-learning system)。我们将非常简要地解释什么是神经网络及其工作原理。
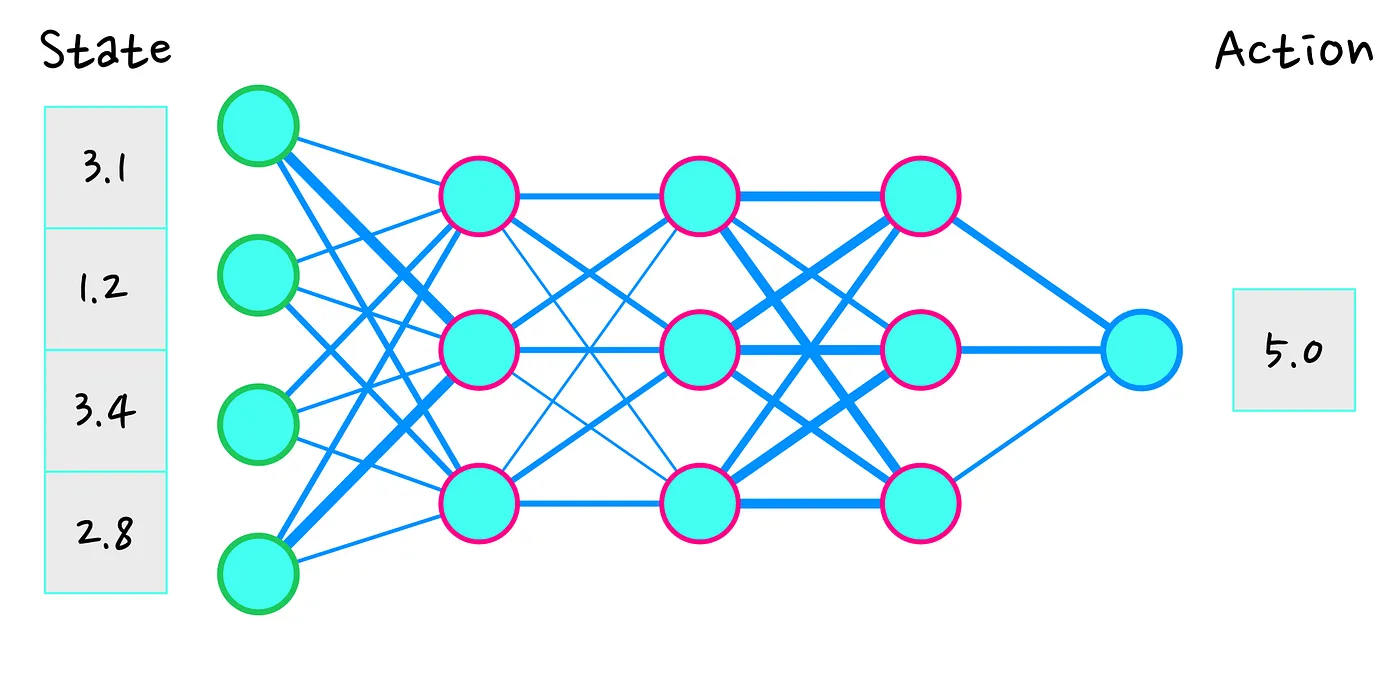
神经网络(NN)是基于人脑的一种不精确地(loosely)学习结构。它由神经元(neurons,图中的青色点)和突触(synapses,蓝点之间的蓝线)组成。当您查看神经网络时,您可以看到它具有许多蓝点组成的“列”,我们将其称为层(layers)。第一层(带有绿色边缘的蓝点)我们称为“输入层”(input layer)。最后一层(带有蓝色边缘的单个神经元)我们称为“输出层”(output layer)。
神经网络的工作原理是从输入层(input layer)将一些数字作为输入开始。这种输入类似于到达大脑并穿过大脑的电信号。突触(连接)增强或减弱信号。然后在到达下一层的新神经元之前组合来自各个神经元的信号。如果信号足够强,神经元将“激发”并进一步传播信号,如果信号不够强,则不会传播信号。这个过程持续进行,直到信号到达输出层(output layer),从而给我们一个输出。在我们的例子中,网络的输入是状态,输出的数字是智能体的行为。
神经网络初始是随机连接的,因此信号也会随机增强和减弱,从而产生随机输出/行为(ouput/action)。现在的技巧是我们改变连接,使神经网络产生更接近我们预期的输出。你可以把神经网络看作一个有很多旋钮的大机器,现在我们需要弄清楚如何转动旋钮直到它产生令人满意的输出。我们可以使用数学,通过称为反向传播(backpropagation)的算法来做到这一点。但在此处我们将省略细节。
还记得我们在谈论策略时提到的参数吗?就神经网络而言,它们实际上指的是这些连接!改变连接是我们改变策略产生输出的方式。
我们已经涵盖了很多内容,并且几乎准备好完成这篇充满定义和符号的文章。我向你保证,当我们稍后对这些算法进行实际编码时,它们都会很有用!
轨迹与回报(Trajectories and returns)
一旦了解了状态和行为,轨迹(trajectories)就很容易理解。轨迹指某些状态和动作的序列:
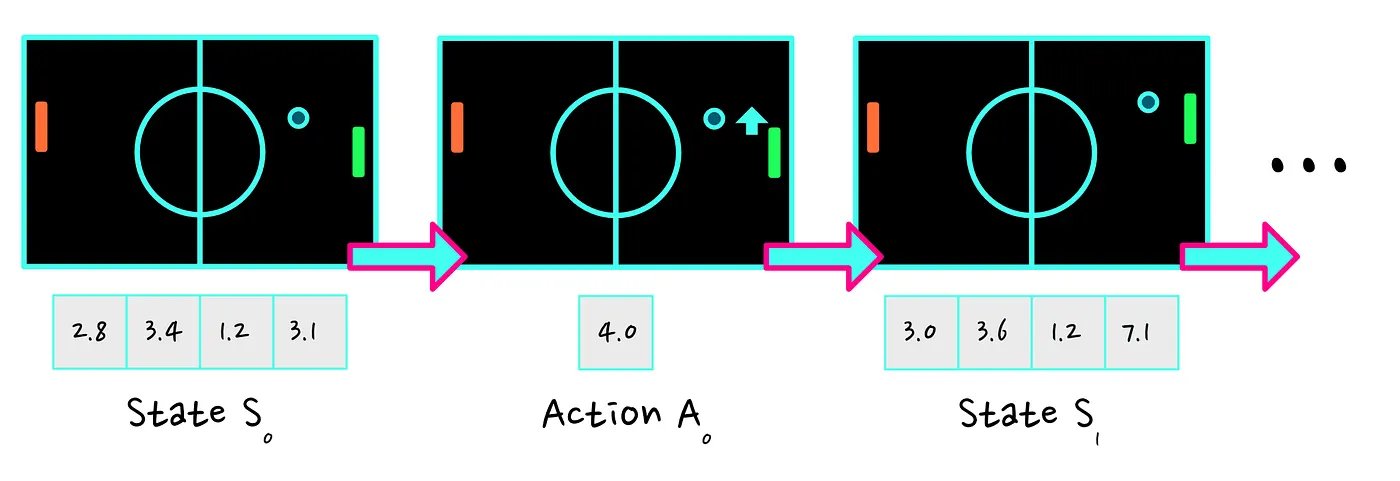
在轨迹结束时,我们的智能体将积累(accumulated)一定数量的奖励(rewards)。这个累积的奖励就是我们所说的回报(return)。
我们分为有限范围(infinite-horizon)回报和无限范围(infinite-horizon)回报。有限范围意味着我们的轨迹仅包含有限数量的时间步长,而无限范围意味着我们将计算无限时间步长的回报。
这是**有限范围回报(finite-horizon return)**的公式。我们有一个轨迹 ,我们可以根据它计算回报 。在公式中,我们对时间步长 的每个 求和,直到范围 。
无限范围回报(infinite-horizon return)的公式非常类似有限范围回报公式,只是我们现在对理论上的无限个时间步长进行求和,并且引入了一个新变量 。 (gamma)是折扣因子(discount factor),其值始终在 0 和 1(含)之间。折扣系数越低,未来奖励的价值就越低。
折扣因子在数学上有既方便又直观的解释。它很方便,因为对于具有无限时间步长的问题,我们知道它将收敛(converge)到有限值。另一方面,我们也很直观地认为,通常尽早获得奖励比晚获得奖励更好。例如,现在获取现金比以后获取现金更好,因为由于通货膨胀,现金以后可能会贬值。
价值函数和Q-函数(Value function and Q-function)
在强化学习中,我们希望为我们的智能体找到一种策略(一种行为,a behaviour),使其获得尽可能高的累积奖励。为了发现这个策略,我们可以定义一些其他有用的函数,例如价值函数(Value function)。价值函数如下所示:
您可以将这个公式解读为:“在策略 下行动时,处于状态 的价值等于我们期望从策略 遵循的轨迹 获得的奖励,假设状态 是起始状态”。或者简而言之,**它大致告诉我们处于某种状态有多好。**该公式中的“ ”代表“期望(expectation)”。这是我们期望从策略 中获得的轨迹,如果你愿意的话,也可以是平均轨迹。
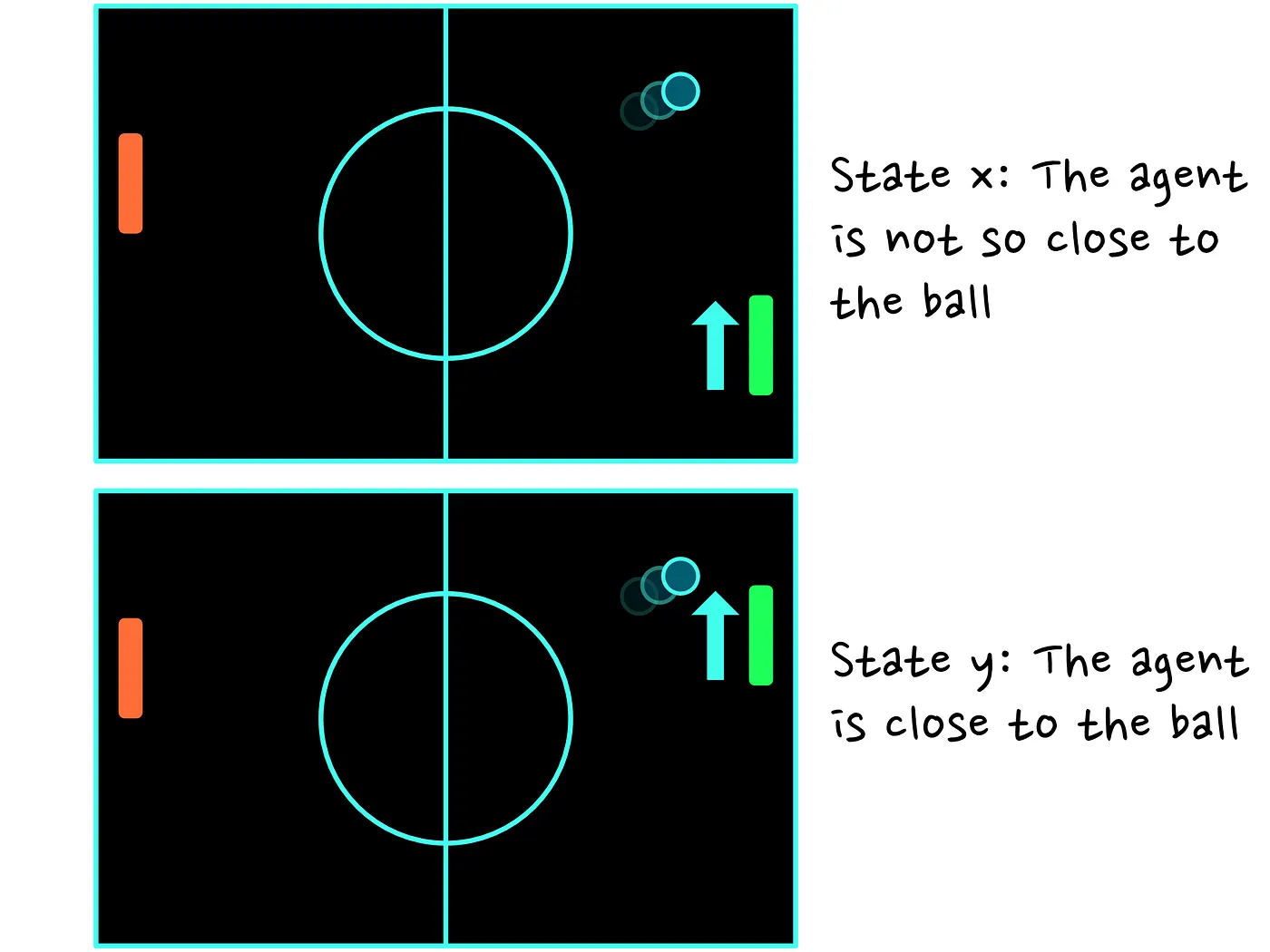
请查看示例中的上图。智能体距离球很远,而在下图中,智能体离球非常近。如果我们的智能体有一个策略让他向球移动,那么状态 的值很可能高于状态 的值。原因是在状态 下,我们的智能体可能无法做出及时传球,从而使他失去了得分。
另一个非常有用的函数是 Q-函数(Q-function)。它看起来像这样:
如您所见,它看起来与价值函数非常相似,实际上也很相似,只是有一个细微(subtle)的差别。该函数表示:“在策略 下,处于状态 并采取行动 的价值等于我们期望从策略 遵循的轨迹 获得的奖励,假设 是起始状态,我们采取的第一个行动是 ”或者简而言之,它告诉我们处于一种状态并采取某种行动有多好。
这两个函数都经常在强化学习算法中使用。他们有一整套与之相关的算法。例如,Q-学习(Q-learning)算法基于这样一个事实:如果您知道某个状态下所有可能操作的 Q-值(Q-value),那么您就可以决定最好采取哪种操作。您只需选择具有最高值 Q-函数(Q-function)的操作即可获得最优策略。
不幸的是,在大多数情况下,我们无法准确地知道价值函数(Value function)或 Q-函数(Q-function),因此在实践中我们将使用学习算法(如神经网络)来估计/学习它们。
结论(Conclusion)
这是一篇很长的文章,充满了术语,但你做到了!讨论完所有这些概念后,将为您开始实现自己的算法奠定坚实的基础。在下一部分中我们将讨论 REINFORCE 算法。 REINFORCE 算法在概念上很简单,但却是策略梯度算法族(the policy gradient-family of algorithms)的核心。感谢您的阅读,下一部分见!

