译注:强化学习简介(第 1 部分)
- 说明
- Reinforcement Learning: An introduction (Part 1/4)
- 听起来很酷! ……但是我能用强化学习做什么呢?
- 强化学习如何融入大局?(How does RL fit in the bigger picture?)
- 如果强化学习如此出色,为何不是每个人都使用呢?
- 总结
说明
本文是对 Cédric Vandelaer 强化学习简介(Reinforcement Learning: An introduction)系列译注。仅供学习交流之用!
原文包含 4 部分,此是第 1 部分。
原文链接:Reinforcement Learning: An introduction (Part 1/4)
原文作者:Cédric Vandelaer
Reinforcement Learning: An introduction (Part 1/4)
Hi,欢迎来到强化学习(Reinforcement Learning,RL)简介系列第一部分。

如果之前您没听说过强化学习(RL),那么让我来总结下:“RL 是训练人工智能模型以解决特定任务(certain task)或目标的通用框架”……或者用外行人的(layman’s)话来说,我们让人工智能(artificial intelligence,AI)做很酷的事!
本系列博客的目标是了解 RL 并同时探索之后会提到的一些最新研究。我们将从最基础的内容开始,逐步探讨更高级的话题。即使您之前几乎没有编程和/或数学知识,您也应该能够非常顺利地跟上(follow)。
这个小系列被分为四部分:
同时,这个小系列是以越来越复杂、不断地增加的方式介绍后续帖子的。如果您已经熟悉内容,请随意跳到下一部分。
译注: REINFORCE 是 'REward Increment Non-negative Factor times Offset Reinforcement times Characteristic Eligibility 的缩写。
Fun Fact: REINFROCE is an acronym for " 'RE’ward 'I’ncrement 'N’on-negative 'F’actor times 'O’ffset 'R’einforcement times 'C’haracteristic 'E’ligibility. => Info from: gymnasium tutorials.
听起来很酷! ……但是我能用强化学习做什么呢?
强化学习是学习任何任务的框架。理论上,强化学习可以解决任何马尔可夫决策过程(Markov Decision Process,MDP)的问题。我们稍后会解释这意味着什么。现在,让我们来看看一些成功的应用程序。如果您喜欢这些示例,请务必查看原作者的作品。
通用(General)
我喜欢展示的视频之一是来自 OpenAI 的捉迷藏视频。它是一个展示了强化学习如何帮助我们发现新问题解决方案,而无需明确编程策略或解决方法的很好的例子。
游戏(Games)
深度强化学习(Deep RL,将强化学习与神经网络相结合)的早期成功之一是能够直接从像素学习如何玩 Atari 游戏。后来,研究人员不仅在(相对)简单的 Atari 游戏上评估强化学习,而且在最难的竞技游戏上评估它。这里的假设是,如果强化学习可以解决这些复杂的游戏,它也可以推广到具有挑战性的现实世界环境中。举个例子,这是 Deepmind 的 AlphaStar 在 StarCraft 2(《星际争霸 2》)游戏中与一名职业玩家的较量。
机器人技术(Robotics)
解决模拟和视频游戏中的任务是一回事,但现实生活中又如何呢?强化学习经常应用(或至少前景广阔)的另一个热门领域是机器人技术。由于各种原因,机器人技术比模拟要困难得多。例如,考虑一下让机器人重复尝试某个动作所需的时间。或者考虑一下机器人技术涉及的安全要求。在下面的示例中,您可以看到苏黎世机器人系统实验室(Robotics System Lab in Zürich)的 ANYmal 机器人如何学会从跌倒中恢复站立姿态。
现实世界例子
除了刚才提到的领域之外,强化学习还可以应用于许多其他领域。广告、金融、医疗保健……仅举几例。作为最后一个例子,我展示了一个面向目标的聊天机器人,经过训练可以进行销售谈判 (来源: https://siddharthverma314.github.io/research/chai-acl-2022/ )。

强化学习:基础知识
强化学习框架的描述如下:我们有一个尝试在特定环境(environment)中解决任务的智能体(agent)。这个智能体(agent)的概念应该是非常广泛的,智能体(agent)可以是机器人、聊天机器人、虚拟角色等。在每个时间步(timestep) t,智能体需要选择一个动作(action) a。在此操作之后,它可能会收到奖励(reward) r,并且我们会对其状态(state) s 进行新的观察(observation)。新状态(new state)可以由智能体的操作和智能体运行的环境来确定。
强化学习问题是试图最大化智能体随着时间推移获得的累积奖励。
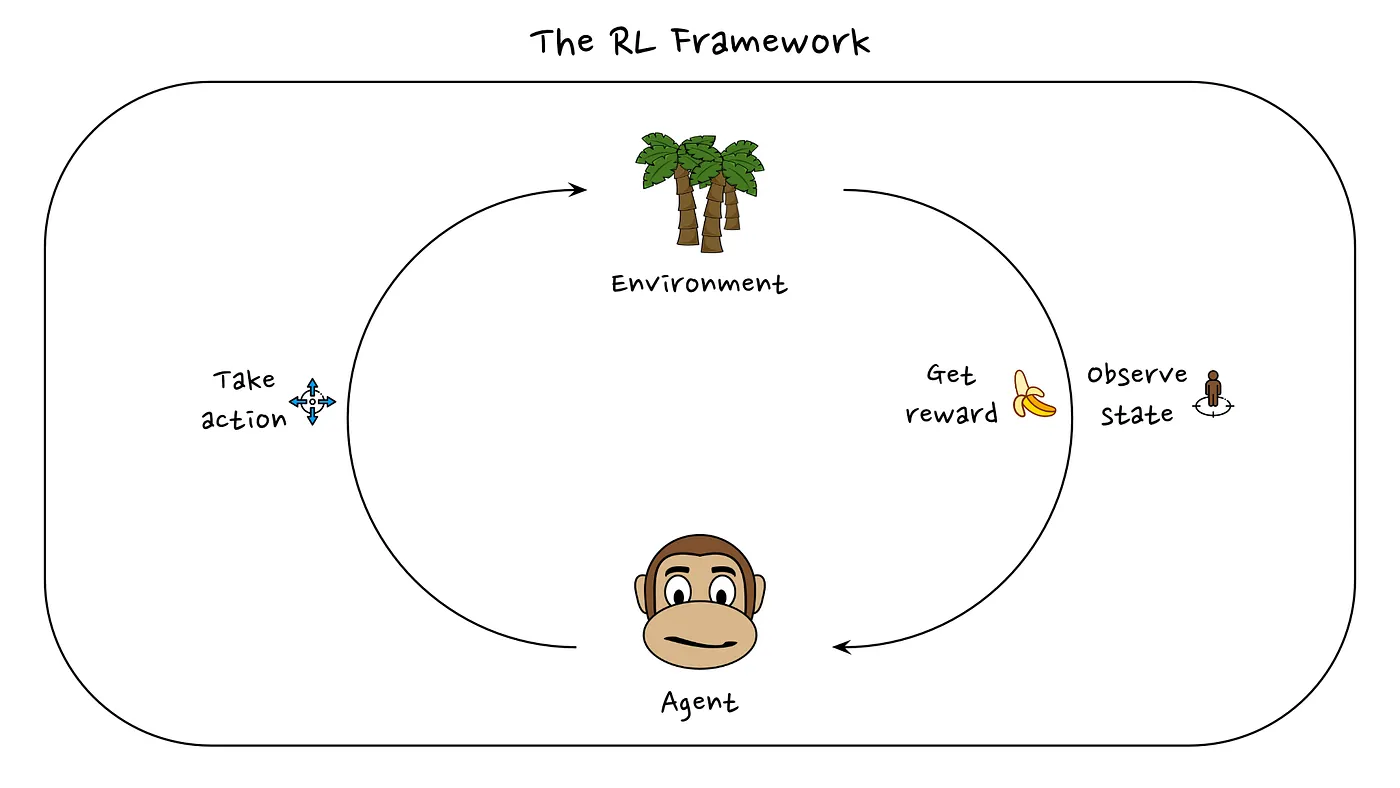
想象我们的智能体是一只猴子,我们希望猴子解决的任务是捡起尽可能多的香蕉。在每一步,猴子都需要决定采取行动。这些动作可以是走向树、抓东西、爬……也许每个时间步的奖励可以定义为猴子在该时间步获得的香蕉数量。每次动作结束后,猴子会处于新状态。也许我们将猴子的状态定义为它在世界上的坐标位置。因此,当猴子迈出一步时,下一个时间步的状态将是猴子在下一个时间步的坐标。我们现在正在寻找最佳行为(optimal behavior),即猴子可以采取的最佳行动序列(the best sequence of actions the monkey can take),以最大化它获得的香蕉总数。
强化学习如何融入大局?(How does RL fit in the bigger picture?)
您可能会看着这个框架并想:“嘿,这不正是人们已经在…领域研究的内容吗?”。事实上,你可能是对的。
在工程或数学等其他领域,人们经常用不同的名称和方法研究相同的问题。或者在神经科学和心理学等领域,大脑通过释放多巴胺来“奖励”我们的方式有一些相似之处。
这种领域交叉的可能原因是,强化学习是对基础问题的研究。它本质上是决策科学。在这些系列中,我们将从计算机科学和机器学习的角度来看待它。

这种普遍适用性也是我个人对强化学习如此感兴趣的原因。强化学习是一种可以让我们更接近通用人工智能的潜在技术:一种可以解决任何任务的人工智能系统,而不是一组狭窄的任务。当然,还有其他技术(例如,大语言模型、图神经网络……)在这方面取得了一些进展,但强化学习的问题表述似乎是最不同凡响。
定位强化学习的另一种方法是观察它与其他学习范例的比较。在机器学习领域,人们通常区分为监督学习(Supervised learning)、无监督学习(Unsupervised learning)和强化学习(Reinforcement learning)。
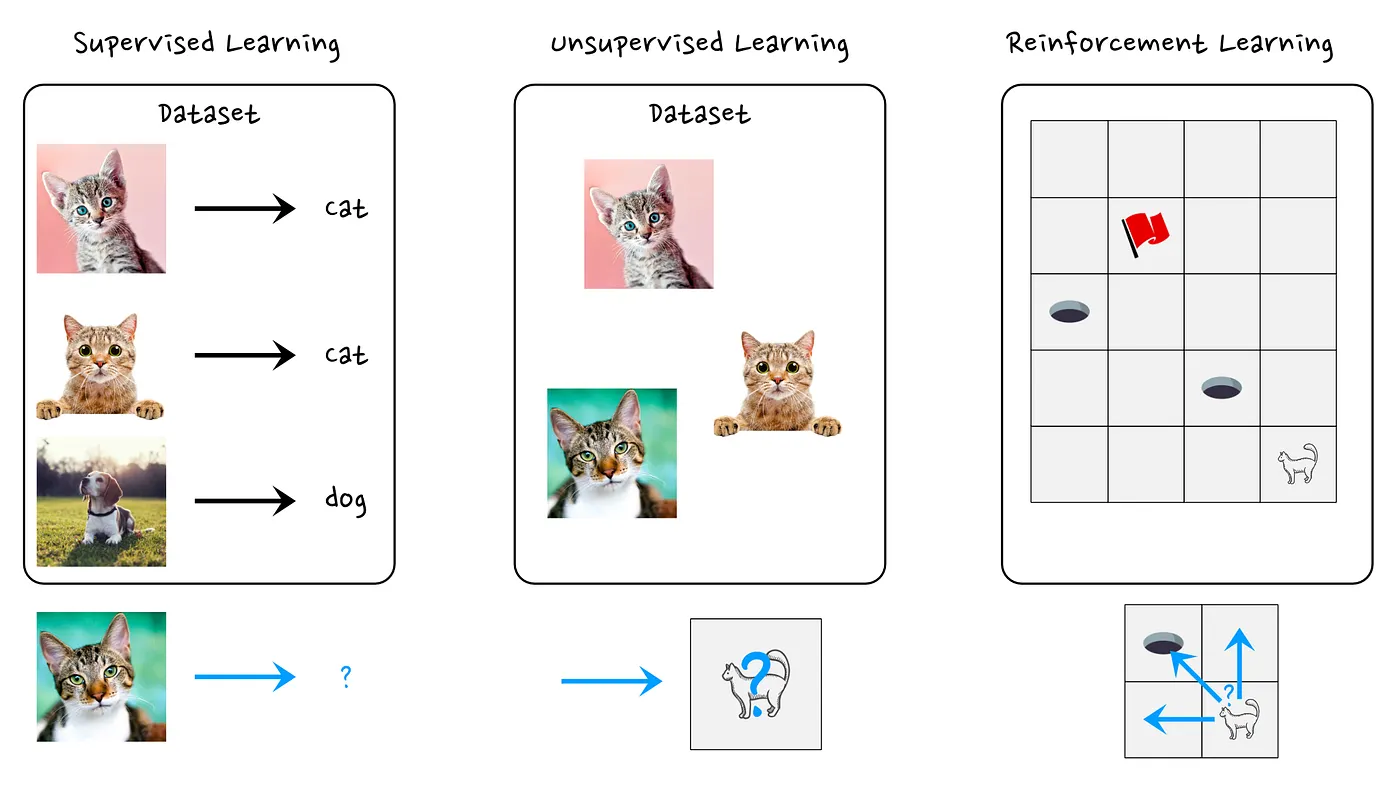
当谈到监督学习时,我们本质上是在尝试学习一个函数,即从 X 到 Y 的映射。我们的数据集(dataset)由样本(sample) X 组成,在训练过程中,我们为 AI 系统提供这些样本应该映射到的标签 Y。当我们的 AI 模型在给定从未见过(unseen)样本 x 的情况下正确预测标签 y 时,它就是成功的。
举个例子,假设我们有猫和狗图像组成的一个数据集。每个样本图像都有一个标签,说明图像是否包含“狗”或“猫”。监督模型的目标是学习如何将狗图像映射到标签“狗”,将猫图像映射到标签“猫”。在学习了这种映射之后,希望这个人工智能模型能够复现对它以前从未见过的新图像进行此过程。
无监督学习环境中,不再提供任何标签 Y。因此,人工智能系统的任务现在变成了学习有关数据集的某些一般统计数据。例如,我们可以赋予人工智能生成新样本的任务,类似于数据集中看到的样本。在这种情况下,如果模型能够正确学习数据集的有关注的特征(learn the interesting characteristics of a dataset),则该模型将被视为成功。
强化学习与上边的范例有很大不同。在强化学习范例中,我们考虑一个与环境主动交互的智能体。通过交互,可能会影响运行的环境。这里我们需要考虑的“数据集”是智能体采取的行动以及通过采取这些行动获得的累积奖励。这里的另一个困难是我们的数据集是非静态(non-static)的。假设我们的智能体以某种方式行事,然后我们可以收集智能体所采取操作的一些数据,并且可以尝试优化这些数据(例如,执行更多趋向成功结果的操作)。但由于这种优化,我们现在改变了该智能体的行为,因此需要收集新数据以用来了解智能体现在的表现如何。
译注:此处有关强化学习的描述,结合上边的 monkey agent 理解会更容易些。
如果强化学习如此出色,为何不是每个人都使用呢?
读完所有这些后,您可能想知道为什么人们不使用强化学习来解决所有可以想到的问题。事实是,尽管该领域在过去几年中取得了很多进步,但仍有一些基本问题需要解决。进展一直在取得,但为了让您了解可能会遇到的情况,我将列出一些常见的问题。
样本(低)效率(Sample (in-)efficiency)**
众所周知,强化学习的样本效率非常低。我们将“样本”视为与环境的交互。强化学习需要大量样本/交互才能解决一个任务。从这个意义上说,强化学习与人类相比效率非常低,例如,人类不需要花费数十个小时来学习如何玩 Atari 游戏。
这种样本效率可以部分解释为人类在遇到新任务时可以利用大量先前的知识(先验知识)。例如,人类可以重复使用先前的游戏知识和技能和/或他们人生经历中获得的其他经验。相反地,强化学习智能体在没有任何假设的情况下开始学习过程。
另外,值得一提的是,利用先前任务中的知识也是个活跃的研究课题。我只举一个例子(众多例子中的一个)来给你一些想法。

探索与利用的权衡(The exploration-exploitation trade-off)
虽然上一个问题听起来更像是工程工作(事实并非如此),但探索与利用的权衡似乎更为根本。每当我们训练一个强化学习智能体(RL-agent)时,智能体都需要一些时间去探索,需要采取一些以前没有采取过的行动,以便发现如何解决问题。另一方面,我们不能让智能体总是采取随机行动,因为这些随机行动可能不会导致任何结果。有时我们希望智能体利用它已经学到的知识来尝试进一步优化。这就是探索与利用的权衡,我们想要一种自动化的让智能体在探索和采取已知行动会导致什么结果的行动之间取得良好的平衡方式。
对于很多问题,智能体很可能陷入局部最优。

探索与利用的权衡一开始听起来很容易处理,但事实证明这是强化学习最难解决的问题之一。让您了解这个问题有多难:这个问题最初是由盟军的科学家考虑的,但建议将其交给德国,因为它被认为非常棘手,以至于他们希望德国科学家也在这上面浪费时间。
译注:夺笋啊 0vO
目前还没有找到解决这个问题的灵丹妙药,并且有很多人正在研究各种解决方案。我将在此处留下一个链接,指向之前提出的名为“好奇心驱动的探索(curiosity-driven exploration)”的解决方案,我发现该解决方案特别有趣。
Curiosity-driven exploration by Self-supervised Prediction
稀疏奖励问题(The sparse-reward problem)
另一个基本的问题是所谓的稀疏奖励(Sparse-reward)问题。顾名思义,当我们的强化学习智能体收到的奖励太少,以至于它实际上没有得到关于如何改进的反馈(feedback)时,就会出现这个问题。
想象一下这辆山地车。智能体需要左右移动汽车,以便获得足够的动力到达顶部。但最初,智能体并不知道它需要来回移动汽车才能到达顶部。如果我们只在到达标志处时才给智能体奖励(正反馈信号,a positive feedback signal),它可能永远不会得到正反馈信号,因为它可能永远不会通过采取随机操作(exploration,探索)到达标志处。

解决这个问题的常用方法是“奖励塑造(reward shaping)”。我们将修改奖励,以便智能体获得更多反馈信号来学习。例如,对于山地汽车,我们还可以根据智能体达到的速度或高度给予其积极的奖励。然而,奖励塑造并不是一个可扩展的解决方案(scalable solution)。幸运的是,人们正在寻求其他解决办法。
我在这里留下另一个例子,我认为这是一个有趣的(但不是普遍适用的方法)来抵消稀疏奖励。
上述问题只是一些突出的例子,但事实上,一些更聪明的人正在研究更多的问题。好消息是正在取得定期、稳定的进展。
总结
哟吼~,在很短的时间内有很多信息,但你还是成功了!第一篇介绍应该能让您对强化学习有一个全局的了解。

在下一篇文章中,我们将开始正式化这篇文章中简要提到的一些想法和概念,作为我们亲自动手实现这些想法的准备。

