1. 事务基本概念
1.1 事务
Transactions are atomic units of work that can be committed or rolled back. When a transaction makes multiple changes to the database, either all the changes succeed when the transaction is committed, or all the changes are undone when the transaction is rolled back.
Database transactions, as implemented by
InnoDB, have properties that are collectively known by the acronym ACID, foratomicity,consistency,isolation, anddurability.
事务:transaction,一个可提交或回滚的原子性工作单元。在一个事务中对数据库的多次变更,要么在提交( commit )时都更改成功,要么在回滚(roll back)时撤销所有变更。事务具有 ACID 特性。
1.2 提交
A
SQL statementthat ends atransaction, making permanent any changes made by the transaction. It is the opposite ofrollback, which undoes any changes made in the transaction.InnoDB uses an optimistic mechanism for commits, so that changes can be written to the data files before the commit actually occurs. This technique makes the commit itself faster, with the tradeoff that more work is required in case of a rollback.
By default, MySQL uses the autocommit setting, which automatically issues a commit following each SQL statement.
提交:commit 是事务结束的 SQL 语句使事务所做的任何更改持久化。提交使用乐观锁机制以便在数据实际发生提交之前可以改变。与roolback相反,回滚会撤销事务中所做的任何更改。MySQL 默认会在每个 SQL 语句之后自动提交发出提交。
1.3 回滚
A
SQL statementthat ends atransaction, undoing any changes made by the transaction. It is the opposite ofcommit, which makes permanent any changes made in the transaction…By default, MySQL uses the autocommit setting, which automatically issues a commit following each SQL statement. You must change this setting before you can use the rollback technique.
回滚:rollback 是事务结束的SQL 语句,用来撤销事务所做的任何更改。与commit相反,提交会持久化事务所做的任何更改。因 MySQL 默认会在每个 SQL 语句之后自动提交发出提交,故使用rollback之前,必须更改以禁止自动提交。
需要注意的是,一些 DDL 语句是不能被回滚的,诸如 创建或删除表、修改表结构的语句或存储例程。
Some statements cannot be rolled back. In general, these include data definition language (DDL) statements, such as those that create or drop databases, those that create, drop, or alter tables or stored routines.
You should design your transactions not to include such statements. If you issue a statement early in a transaction that cannot be rolled back, and then another statement later fails, the full effect of the transaction cannot be rolled back in such cases by issuing a ROLLBACK statement.
1.4 事务特性
An acronym standing for
atomicity,consistency,isolation, anddurability. These properties are all desirable in a database system, and are all closely tied to the notion of a transaction. The transactional features of InnoDB adhere(遵守) to the ACID principles.Transactions are atomic units of work that can be committed or rolled back. When a transaction makes multiple changes to the database, either all the changes succeed when the transaction is committed, or all the changes are undone when the transaction is rolled back.
The database remains in a consistent state at all times — after each commit or rollback, and while transactions are in progress. If related data is being updated across multiple tables, queries see either all old values or all new values, not a mix of old and new values.
Transactions are protected (isolated) from each other while they are in progress; they cannot interfere with each other or see each other’s uncommitted data. This isolation is achieved through the locking mechanism. Experienced users can adjust the isolation level, trading off less protection in favor of increased performance and concurrency, when they can be sure that the transactions really do not interfere with each other.
The results of transactions are durable: once a commit operation succeeds, the changes made by that transaction are safe from power failures, system crashes, race conditions, or other potential dangers that many non-database applications are vulnerable to. Durability typically involves writing to disk storage, with a certain amount of redundancy to protect against power failures or software crashes during write operations. (In InnoDB, the doublewrite buffer assists with durability.)
事务特征:
-
Atomicity原子性。指一个事务是原子的工作单元,不可拆分。当一个事务中包含对数据的多次更改时,要么在
commit提交事务时所有更改都成功,要么在rollback回滚时撤销所有更改。 -
Consistency一致性。事务
commit或rollback之后和事务进行中,数据库保持一致状态。如跨多表更改相关数据,那么查询将看到所有的旧值或所有的新值,而不会看到新旧两种值混合的情况。 -
Isolation隔离性。多个事务进行过程中,各个事务相互之间隔离保护。彼此之间不能相互干预或看到未提交的数据。隔离使用锁定(
locking)机制实现。可通过调整隔离级别在确定事务互不干扰的情况下,以较少的保护换取更高的性能和并发性。 -
Durablility持久性。一旦事务
commit提交成功,该事务做的更改会持久化到系统磁盘。不会受其他如电源故障、系统奔溃、等影响。
2. 事务隔离级别
事务的隔离级别指的是事务 ACID 特性中 I ——隔离性的不同级别。从上边的描述可以看出,事务的隔离(或保护)是通过锁定(locking)机制实现的,这过程中会设计 锁 的实现、作用范围等。此处主要讨论,从事务角度出发,隔离性的几个级别。
不同的隔离级别在某些特定条件下会发生不同的读现象,进而可能会出现违背 事务 ACID 特性的情况。
然而,在不同的应用场景下,我们可以通过调整不同的隔离级别来实现 保护、性能 与 并发 之间的平衡。
2.1 隔离级别
MySQL InnoDB 事务隔离级别有,可串行、可重复读、读已提交、读未提交。
One of the foundations of database processing. Isolation is the
Iin the acronym ACID; the isolation level is the setting that fine-tunes the balance between performance and reliability, consistency, and reproducibility of results when multiple transactions are making changes and performing queries at the same time.From highest amount of consistency and protection to the least, the isolation levels supported by InnoDB are: SERIALIZABLE, REPEATABLE READ, READ COMMITTED, and READ UNCOMMITTED.
With
InnoDBtables, many users can keep the default isolation level (REPEATABLE READ) for all operations. Expert users might choose the READ COMMITTED level as they push the boundaries of scalability with OLTP processing, or during data warehousing operations where minor inconsistencies do not affect the aggregate results of large amounts of data. The levels on the edges (SERIALIZABLE and READ UNCOMMITTED) change the processing behavior to such an extent that they are rarely used.
隔离级别:多个事务同时进行更改和查询时,性能、可靠性、一致性和结果再现性之间平衡的一种设置。InnoDB 支持的隔离级别的一致性保护从高到低依次是:SERIALIZABLE, REPEATABLE READ, READ COMMITTED, READ UNCOMMITTED。
2.2 可串行级别(SERIALIZABLE)
The isolation level that uses the most conservative(保守的) locking strategy, to prevent any other transactions from inserting or changing data that was read by this transaction, until it is finished. This way, the same query can be run over and over within a transaction, and be certain to retrieve the same set of results each time. Any attempt to change data that was committed by another transaction since the start of the current transaction, cause the current transaction to wait.
This is the default isolation level specified by the SQL standard. In practice, this degree of strictness is rarely needed, so the default isolation level for
InnoDBis the next most strict, REPEATABLE READ.
可串行的:此级别事务阻止其他事务插入或更改此事务被读的数据,直到事务完成。是最保守的锁策略。
因采用最保守(悲观)锁策略,故而此种模式下不会发生以下提到的几种读现象。与此同时,此隔离级别较其它几种相比,事务拥有最高的隔离保护,但性能、 并发却都是最低的 。
2.3 可重复读级别(REPEATABLE READ)
The default isolation level for
InnoDB. It prevents any rows that are queried from being changed by other transactions, thus blocking non-repeatable reads but not phantom reads. It uses a moderately strict locking strategy so that all queries within a transaction see data from the same snapshot, that is, the data as it was at the time the transaction started.When a transaction with this isolation level performs
UPDATE ... WHERE,DELETE ... WHERE,SELECT ... FOR UPDATE, andLOCK IN SHARE MODEoperations, other transactions might have to wait.
SELECT ... FOR SHAREreplacesSELECT ... LOCK IN SHARE MODEin MySQL 8.0.1, butLOCK IN SHARE MODEremains available for backward compatibility.
可重复读:此级别可防止其他事务变更被当前事务查询的任何行,进而阻止不可重复读而不是幻读。一般锁策略。InnoDB 的默认隔离级别。
在此隔离级别下事务执行UPDATE ... WHERE ,DELETE ... WHERE ,SELECT ... FOR UPDATE,LOCK IN SHARE MODE 操作时,其它事务可能需要等待。
2.4 读已提交级别(READ COMMITTED)
An isolation level that uses a locking strategy that relaxes some of the protection between transactions, in the interest of performance. Transactions cannot see uncommitted data from other transactions, but they can see data that is committed by another transaction after the current transaction started. Thus, a transaction never sees any bad data, but the data that it does see may depend to some extent on the timing of other transactions.
When a transaction with this isolation level performs
UPDATE ... WHEREorDELETE ... WHEREoperations, other transactions might have to wait. The transaction can performSELECT ... FOR UPDATE, andLOCK IN SHARE MODEoperations without making other transactions wait.
SELECT ... FOR SHAREreplacesSELECT ... LOCK IN SHARE MODEin MySQL 8.0.1, butLOCK IN SHARE MODEremains available for backward compatibility.
读已提交:此级别下的当前事务不能看到其他事务未提交时的数据,但可以看到其他事务已提交后的数据。使用一种宽松的锁策略,有利于性能。
在此隔离级别下事务执行UPDATE ... WHERE 或 DELETE ... WHERE操作时,其它事务可能等待。事务可以执行 SELECT ... FOR UPDATE 和 LOCK IN SHARE MODE 操作以使其它事务不用等待。
2.5 读未提交级别(READ UNCOMMITTED)
The isolation level that provides the least amount of protection between transactions. Queries employ a locking strategy that allows them to proceed in situations where they would normally wait for another transaction. However, this extra performance comes at the cost of less reliable results, including data that has been changed by other transactions and not committed yet (known as
dirty read). Use this isolation level with great caution, and be aware that the results might not be consistent or reproducible, depending on what other transactions are doing at the same time. Typically, transactions with this isolation level only do queries, not insert, update, or delete operations.
读未提交:此级别事务可以读到其他事务已更改但尚未提交的数据,提供隔离之间事务最少的保护。此隔离级别有可能发生 脏读现象。
3. 事务引起的各种读现象
在不同事务隔离级别下,多个事务的并发运行会有不同的“隔离保护”,当一个事务在读数据,而其他事务在写数据时。读数据的事务有可能会出现脏读、不可重复读、幻读等现象发生。
3.1 读现象
Phenomena such as dirty reads, non-repeatable reads, and phantom reads which can occur when a transaction reads data that another transaction has modified.
读现象:当一个事务读数据而另一个事务已修改了此数据时,可能会发生脏读、不可重复读、幻读等现象。
3.2 脏读现象
An operation that retrieves unreliable data, data that was updated by another transaction but not yet committed. It is only possible with the isolation level known as read uncommitted.
This kind of operation does not adhere to the ACID principle of database design. It is considered very risky, because the data could be rolled back, or updated further before being committed; then, the transaction doing the dirty read would be using data that was never confirmed as accurate.
Its opposite is consistent read, where
InnoDBensures that a transaction does not read information updated by another transaction, even if the other transaction commits in the meantime.
脏读:读到了另一个事务还未提交的不可靠数据。此类操作同样是违背数据库设计 ACID 原则的。此种现象只在隔离级别是读未提交(READ UNCOMMITTED)的情况下才有可能发生。与其相反的是一致性读(consistent read),一致性读由 InnoDB 担保事务不会读到另一个事务更新的数据,即使在此期间另一个事务已经提交。
注:下文将会介绍 InnoDB 使用 MVCC 会保证 一致性读,避免出现脏读现象。
3.3 不可重复读现象
The situation when a query retrieves data, and a later query within the same transaction retrieves what should be the same data, but the queries return different results (changed by another transaction committing in the meantime).
This kind of operation goes against the
ACIDprinciple of database design. Within a transaction, data should be consistent, with predictable and stable relationships.Among different isolation levels,
non-repeatable readsare prevented by theserializable readandrepeatable readlevels, and allowed by theconsistent read, andread uncommittedlevels.
不可重复读现象:同一事务中后续查询应该出现相同的数据,但是查询返回了在此期间另一个事务提交更改的结果数据。此类操作同样是违背数据库设计 ACID 原则的。
事务隔离级别为可串行读和可重复读可以防止此种现象的发生,一致性读和读未提交级别允许此种现象发生。
注:此处的consistent read直译是一致性读。按原文上下描述推理,以及后续对 consistent read 的定义来看,此处当指使用了一致性快照读操作的隔离级别,即 可重复读 和 读已提交 隔离级别。
3.4 幻读现象
A row that appears in the result set of a query, but not in the result set of an earlier query. For example, if a query is run twice within a transaction, and in the meantime, another transaction commits after inserting a new row or updating a row so that it matches the
WHEREclause of the query.This occurrence is known as a phantom read. It is harder to guard against than a
non-repeatable read, because locking all the rows from the first query result set does not prevent the changes that cause the phantom to appear.Among different isolation levels, phantom reads are prevented by the
serializable readlevel, and allowed by therepeatable read,consistent read, andread uncommittedlevels.
幻读:数据出现在当前查询结果集中,而没有出现在早期查询的结果集中。可以理解为,在同一个事务中进行前后两次相同语句的查询时,返回的数据不一致。
它比不可重复读更难防范,因为锁定先前查询结果集中的所有行并不会阻止导致幻象出现的更改。
4. 读策略简介
读按照是否上锁可大体上分为,锁读与非锁读。在不同事务隔离级别下使用不同的读策略。
其中非锁读以 MVCC 为主要。MVCC 使用快照、读视图等机制,解决了事务并发过程中读数据可能发生多次查询不一致的现象(——脏读)。在特定隔离级别下事务会根据时间点创建读视图,以使事务之间做隔离保护。允许查询在其它事务持有锁的情况下无须等待即可继续进行。这种技术提高了 并发。
4.1 快照
A representation of data at a particular time, which remains the same even as changes are committed by other transactions. Used by certain isolation levels to allow consistent reads.
快照:表示一个特定时间的数据,即使其它事务提交了更改,数据也会保持不变。在某些隔离级别中使用,以允许一致性读。
4.2 锁定
The system of protecting a transaction from seeing or changing data that is being queried or changed by other transactions. The locking strategy must balance reliability and consistency of database operations (the principles of the ACID philosophy) against the performance needed for good concurrency. Fine-tuning the locking strategy often involves choosing an isolation level and ensuring all your database operations are safe and reliable for that isolation level.
锁定:一个保护事务正在被查看或更改的数据不被其他事务查询或更改的系统。
注意:锁定更多的描述的是一个过程、系统,锁更多的是方式、策略。锁定 会使用 锁。有关锁按照大的分类可有 共享锁、排它锁,这两类锁的实现模式也有多种,具体可参考:InnoDB Locking ,此处不多叙述。
4.3 锁定读
A
SELECTstatement that also performs a locking operation on anInnoDBtable. EitherSELECT ... FOR UPDATEorSELECT ... LOCK IN SHARE MODE. It has the potential to produce a deadlock, depending on the isolation level of the transaction. The opposite of a non-locking read. Not allowed for global tables in a read-only transaction.
SELECT ... FOR SHAREreplacesSELECT ... LOCK IN SHARE MODEin MySQL 8.0.1, but LOCK IN SHARE MODE remains available for backward compatibility.
锁定读:指使用了锁定操作的查询语句。
使用锁定读可能出现死锁。在访问模式为只读的全局表中不允许使用。与锁定读 (locking read) 相反的是非锁定读 (non-locking read)
有关 锁定读 的信息,可参考:Locking Reads 。
4.4 非锁定读
A query that does not use the
SELECT ... FOR UPDATEorSELECT ... LOCK IN SHARE MODEclauses. The only kind of query allowed for global tables in a read-only transaction. The opposite of a locking read. See Section 15.7.2.3, “Consistent Nonlocking Reads”.
SELECT ... FOR SHAREreplacesSELECT ... LOCK IN SHARE MODEin MySQL 8.0.1, butLOCK IN SHARE MODEremains available for backward compatibility.
非锁定读:指没有使用锁定操作的查询语句。与锁定读 (locking read) 相反。
有关非锁定读,可参考:Consistent Nonlocking Reads。
4.5 一致性读
A read operation that uses
snapshotinformation to present query results based on a point in time, regardless of changes performed by other transactions running at the same time. If queried data has been changed by another transaction, the original data is reconstructed based on the contents of theundo log. This technique avoids some of the locking issues that can reduce concurrency by forcing transactions to wait for other transactions to finish.With
REPEATABLE READisolation level, the snapshot is based on the time when the first read operation is performed. WithREAD COMMITTEDisolation level, the snapshot is reset to the time of each consistent read operation.Consistent read is the default mode in which
InnoDBprocessesSELECTstatements inREAD COMMITTEDandREPEATABLE READisolation levels. Because a consistent read does not set any locks on the tables it accesses, other sessions are free to modify those tables while a consistent read is being performed on the table.…
A consistent read means that InnoDB uses multi-versioning to present to a query a snapshot of the database at a point in time. The query sees the changes made by transactions that committed before that point in time, and no changes made by later or uncommitted transactions. The exception to this rule is that the query sees the changes made by earlier statements within the same transaction. This exception causes the following anomaly: If you update some rows in a table, a
SELECTsees the latest version of the updated rows, but it might also see older versions of any rows. If other sessions simultaneously update the same table, the anomaly means that you might see the table in a state that never existed in the database.If the transaction isolation level is
REPEATABLE READ(the default level), all consistent reads within the same transaction read the snapshot established by the first such read in that transaction. You can get a fresher snapshot for your queries by committing the current transaction and after that issuing new queries.For technical details about the applicable isolation levels, see Section 15.7.2.3, “Consistent Nonlocking Reads”.
一致性读:一个忽略同时运行的其它事务所做的更改,使用快照信息根据时间点显示查询结果的读操作。如果查询期间数据已被另一个事物更改,则根据 undo log 的内容重建原始数据。一致性读避免了 锁定 问题,其 不会对其访问的表设置任何锁,因此其它会话可以自由修改这些表。
一致性读是 InnoDB 在 可重复读 和 读已提交 隔离级别下处理 SELECT 语句的默认模式。
4.6 undo log
A storage area that holds copies of data modified by active transactions. If another transaction needs to see the original data (as part of a consistent read operation), the unmodified data is retrieved from this storage area.
In MySQL 5.6 and MySQL 5.7, you can use the
innodb_undo_tablespacesvariable have undo logs reside in undo tablespaces, which can be placed on another storage device such as an SSD. In MySQL 8.0, undo logs reside in two default undo tablespaces that are created when MySQL is initialized, and additional undo tablespaces can be created usingCREATE UNDO TABLESPACEsyntax.The undo log is split into separate portions, the insert undo buffer and the update undo buffer.
…
An undo log is a collection of undo log records associated with a single read-write transaction. An undo log record contains information about how to undo the latest change by a transaction to a clustered index record. If another transaction needs to see the original data as part of a consistent read operation, the unmodified data is retrieved from undo log records. Undo logs exist within undo log segments, which are contained within rollback segments. Rollback segments reside in undo tablespaces and in the global temporary tablespace.
undo log:保存由活动中事务所修改的数据副本的存储区域。如果另一个事务需要查看原始数据,则从此存储区域检索未修改的数据。此存储区域分为 insert undo buffer 和 update undo buffer。
使用 undo log 可记录事务运行过程中插入或更新数据的每条记录日志。 可参照 InnoDB 架构图做对其局部与整体存储逻辑做初步了解:
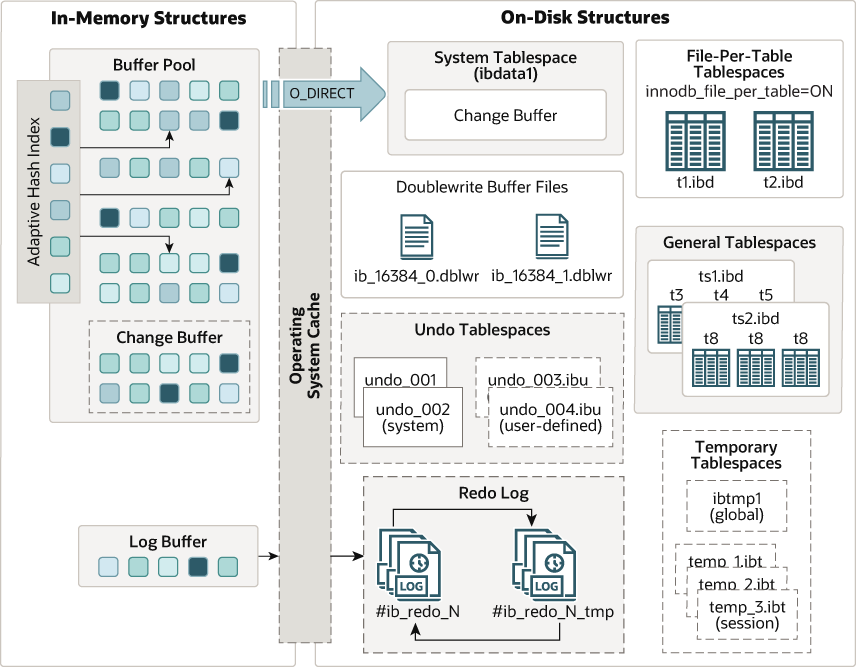
有关 Undo Logs 的详细介绍可参考:Undo Logs
4.7 MVCC 机制
Acronym for “multiversion concurrency control”. This technique lets
InnoDBtransactions with certain isolation levels performconsistent read operations; that is, to query rows that are being updated by other transactions, and see the values from before those updates occurred. This is a powerful technique to increase concurrency, by allowing queries to proceed without waiting due to locks held by the other transactions.This technique is not universal in the database world. Some other database products, and some other MySQL storage engines, do not support it.
MVCC:“MultiVersion Concurrency Control” 首字母缩写。此技术在 InnoDB 事务隔离级别为 consistent read 操作中使用。有利于提高并发。
4.8 读视图
An internal snapshot used by the MVCC mechanism of
InnoDB. Certain transactions, depending on their isolation level, see the data values as they were at the time the transaction (or in some cases, the statement) started. Isolation levels that use aread vieware REPEATABLE READ, READ COMMITTED, and READ UNCOMMITTED.
读视图:InnoDB 的 MVCC 机制使用的内部快照。隔离级别为 可重复读、读已提交、读未提交 时,事务查询数据时会使用 读视图。
5. 隔离级别与读现象关系表
事务隔离级别与读现象的是否发生可总结为:
| 隔离级别 | 脏读 | 不可重复读 | 幻读 | 备注 |
|---|---|---|---|---|
| 串行 | 不会 | 不会 | 不会 | 最保守的锁策略 |
| 可重复读 | 不会 | 不会 | 可能 | 一般适度的锁策略。MySQL InnoDB 默认事务隔离级别。 使用无锁的 MVCC机制下可确保不会有脏读发生。 |
| 读已提交 | 不会 | 可能 | 可能 | 较宽松的锁策略,有利于性能。 在使用无锁的 MVCC 机制下可确保不会有脏读发生。 |
| 读未提交 | 可能 | 可能 | 可能 | 通常应用于只做查询,不做插入、更新、删除操作的场景下 |
不同隔离级别可根据实际应用场景进行综合考虑,再结合隔离保护、性能、并发等特点权衡是否使用锁读或非锁读。
各隔离级别,可使用不同的 锁 做事务间的隔离保护。有关锁的概念,可参考:InnoDB Locking, 此处不做展开讨论。
6. 案例
6.1 预先准备
-
搭建 MySQL 环境,开启两个客户端会话。
-
创建演示库、表。
因MySQLInnoDB引擎的表支持事务,故而创建表时,须为InnoDB引擎。如,执行
CREATE TABLE t (a INT NOT NULL, b INT) ENGINE = InnoDB;可创建表t。 -
关闭
自动提交事务。
因MySQLInnoDB引擎默认会开启自动提交事务,故以下案例进行时,应关闭。如,执行
SELECT @@SESSION.autocommit;可查看当前会话自动提交事务状态。响应体值若为1则代表开启;0指示关闭。执行
SET @@SESSION.autocommit=0;可关闭,SET @@SESSION.autocommit=1;可开启。此案例需关闭,即执行
SET @@SESSION.autocommit=0;。 -
每个案例开始之前需检查当前会话的隔离级别及访问模式。
-
执行
SELECT @@SESSION.transaction_isolation;可查看当前会话事务隔离级别。响应体值若为:REPEATABLE-READ,代表可重复读级别。READ-COMMITTED,为读已提交级别。READ-UNCOMMITTED,为读未提交级别。SERIALIZABLE,为可串行级别。
-
执行
SELECT @@SESSION.transaction_read_only;可查看当前会话事务的访问模式是否为只读。响应体值若为:0,代表否,则事务可读、写。执行SET @@SESSION.transaction_read_only=0;可关闭当前会话事务允许只读,进而允许读写。1, 代表是,则事务只可读。
-
此案例按不同隔离级别进行事务调整,访问模式需为可读写。
-
6.2 可重复读隔离级别 案例 1:无脏读、无不可重复读、无幻读现象发生
案例时序图如下:
sequenceDiagram
actor UserA as 用户 A
participant TxA as 会话 A
actor UserB as 用户 B
participant TxB as 会话 B
Note over UserA,TxB: 可重复读隔离级别:无脏读、无不可重复、无幻读现象 演示
Note right of UserA: 设置 会话A 的事务隔离级别
UserA->>+TxA: 执行: SET SESSION TRANSACTION='REPEATABLE-READ';
TxA-->>-UserA: 返回: Query OK, 0 rows affected (0.00 sec)
Note right of UserA: 关闭 会话A 的事务自动提交
UserA->>+TxA: 执行: SET @@SESSION.autocommit=0;
TxA-->>-UserA: 返回: Query OK, 0 rows affected (0.00 sec)
Note right of UserB: 设置 会话B 的事务隔离级别
UserB->>+TxB: 执行: SET SESSION TRANSACTION='REPEATABLE-READ';
TxB-->>-UserB: 返回: Query OK, 0 rows affected (0.00 sec)
Note right of UserB: 关闭 会话B 的事务自动提交
UserB->>+TxB: 执行: SET @@SESSION.autocommit=0;
TxB-->>-UserB: 返回: Query OK, 0 rows affected (0.00 sec)
Note right of UserA: 开始 会话A 的事务
UserA->>+TxA: 执行: START TRANSACTION;
TxA-->>-UserA: 返回: Query OK, 0 rows affected (0.00 sec)
Note right of UserB: 开始 会话B 的事务
UserB->>+TxB: 执行: START TRANSACTION;
TxB-->>-UserB: 返回: Query OK, 0 rows affected (0.00 sec)
UserA->>+TxA: 插入: INSERT INTO t VALUES (1,2),(2,3),(3,4);
TxA-->>-UserA: 返回: Query OK, 3 rows affected (0.00 sec)
Records: 3 Duplicates: 0 Warnings: 0
UserA->>+TxA: 查询: SELECT * FROM t WHERE a=1;
TxA-->>-UserA: 返回:
+---+------+
| a | b |
+---+------+
| 1 | 2 |
+---+------+
1 row in set (0.00 sec)
Note right of UserB: 会话A 的事务插入数据后,会话B 的事务查不到 => 无 脏读现象
UserB->>+TxB: 查询: SELECT * FROM t WHERE a=1;
TxB-->>-UserB: 返回: Empty set (0.00 sec)
Note right of UserA: 提交 会话A 的事务
UserA->>+TxA: 提交: COMMIT;
TxA-->>-UserA: 结束事务: Query OK, 0 rows affected (0.00 sec)
Note right of UserA: ==== 会话A 的事务至此结束 ====
Note right of UserB: 会话A 的事务提交后,会话B 的事务仍旧查不到 => 无 不可重复读和幻读现象
UserB->>+TxB: 查询: SELECT * FROM t WHERE a=1
TxB-->>-UserB: 返回: Empty set (0.00 sec)
Note right of UserB: 提交 会话B 的事务
UserB->>+TxB: 提交: COMMIT;
TxB-->>-UserB: 结束事务: Query OK, 0 rows affected (0.00 sec)
Note right of UserB: ==== 会话B 的事务至此结束 ====
Note right of UserB: 事务结束后,可查询到事务A 变动的数据
UserB->>+TxB: 查询 : SELECT * FROM t WHERE a=1
TxB-->>-UserB: 返回:
+---+------+
| a | b |
+---+------+
| 1 | 2 |
+---+------+
1 row in set (0.00 sec)
从上边介绍的概念可以看出,可重复读级别使用一致性读多版本( MVCC 使用 读视图 来实现)来保证事务之间的隔离保护。案例中的 SELECT 语句在事务 COMMIT 之前使用的都是各自事务开始那个时间点(—— by the first such read) 的读视图(—— snapshot ),故而是一定不会发生脏读、不可重复读现象的。在此案例中也没有出现幻读现象,然而幻读现象的发生是有可能存在的,具体复现可参考以下案例。
6.3 可重复读隔离级别 案例 2:幻读现象
案例时序图如下:
sequenceDiagram
actor UserA as 用户 A
participant TxA as 会话 A
actor UserB as 用户 B
participant TxB as 会话 B
Note over UserA,TxB: 可重复读隔离级别:幻读现象 演示
Note right of UserA: 设置 会话A 的事务隔离级别
UserA->>+TxA: 执行: SET SESSION TRANSACTION='REPEATABLE-READ';
TxA-->>-UserA: 返回: Query OK, 0 rows affected (0.00 sec)
Note right of UserA: 关闭 会话A 的事务自动提交
UserA->>+TxA: 执行: SET @@SESSION.autocommit=0;
TxA-->>-UserA: 返回: Query OK, 0 rows affected (0.00 sec)
Note right of UserB: 设置 会话B 的事务隔离级别
UserB->>+TxB: 执行: SET SESSION TRANSACTION='REPEATABLE-READ';
TxB-->>-UserB: 返回: Query OK, 0 rows affected (0.00 sec)
Note right of UserB: 关闭 会话B 的事务自动提交
UserB->>+TxB: 执行: SET @@SESSION.autocommit=0;
TxB-->>-UserB: 返回: Query OK, 0 rows affected (0.00 sec)
Note right of UserA: 开始 会话A 的事务
UserA->>+TxA: 执行: START TRANSACTION;
TxA-->>-UserA: 返回: Query OK, 0 rows affected (0.00 sec)
Note right of UserB: 开始 会话B 的事务
UserB->>+TxB: 执行: START TRANSACTION;
TxB-->>-UserB: 返回: Query OK, 0 rows affected (0.00 sec)
Note right of UserA: 此处查询结果集为空
UserA->>+TxA: 查询: SELECT * FROM t WHERE a=4;
TxA-->>-UserA: 返回: Empty set (0.00 sec)
Note right of UserB: 会话B 的事务插入数据
UserB->>+TxB: 查询: INSERT INTO t VALUES (4,5);
TxB-->>-UserB: 返回: Query OK, 1 row affected (0.00 sec)
Note right of UserB: 提交 会话B 的事务
UserB->>+TxB: 提交: COMMIT;
TxB-->>-UserB: 结束事务: Query OK, 0 rows affected (0.00 sec)
Note right of UserB: ==== 会话B 的事务至此结束 ====
Note right of UserA: 会话A 的事务 更新 会话B 事务提交后的数据。注意,上次查询并无 a=4 的数据 !!!
UserA->>+TxA: 更新: UPDATE t SET b=6 WHERE a=4;
TxA-->>-UserA: 返回: Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
Note right of UserA: 会话A 的事务 这次查询读到的数据未出现在先前的结果集中 => 发生 幻读现象!
UserA->>+TxA: 查询: SELECT * FROM t WHERE a=4;
TxA-->>-UserA: 返回: 返回:
+---+------+
| a | b |
+---+------+
| 4 | 6 |
+---+------+
1 row in set (0.00 sec)
Note right of UserA: 提交 会话A 的事务
UserA->>+TxA: 提交: COMMIT;
TxA-->>-UserA: 结束事务: Query OK, 0 rows affected (0.00 sec)
Note right of UserA: ==== 会话A 的事务至此结束 ====
分析:
根据上文中介绍的事务隔离级别、读现象、读策略,以及此案例中的操作步骤,我们在此可以分析一下为何会发生“幻读现象”。
首先,由 隔离级别为 可重复读 以及事务过程中查询使用的是常规 SELECT 可以知道此处使用的是无锁定的一致性读,是使用 MVCC 机制来实现两次 SELECT 查询的。
从 一致性读操作的引文:
With
REPEATABLE READisolation level, the snapshot is based on the time when the first read operation is performed.
我们可以知道,会话 A 第一次执行 SELECT * FROM t WHERE a=4; 时,其返回结果集为空。MVCC 读视图(read view)的内部快照(internal snapshot)就是在这一次读操作(read operation)执行时基于那个时间点(point in time)创建的,为了后续的描述方便,我们将此时间点创建的快照编号,称为SNP_A_0。再次强调:此时,会话A的第一次查询结果集为空。
接下来,会话 B 没有读操作,而是执行了写操作: INSERT INTO t VALUES (4,5); ,紧接着就有提交了事务,结束了事务的生命。故而在 会话 B 事务周期内,是没有创建快照的。根据事务的 持久性 —— ACID 里头的 D 我们可以知道,B 事务结束后,INSERT 的这条数据已经持久化到数据库系统的存储设备上了。
然后,再看会话 A,其执行了写操作:UPDATE t SET b=6 WHERE a=4。且此操作成功执行了,之所以成功是因为事务 B 已 INSERT 的数据写到盘上了。这个时候会话 A 的快照依旧是 SNP_A_0。注意:再强调一下,只有执行读操作才会触发创建快照。
紧接着,会话 A 执行了查询操作:SELECT * FROM t WHERE a=4;。此时,再根据一致性读操作描述的:
If queried data has been changed by another transaction, the original data is reconstructed based on the contents of the
undo log.
我们可以知道,会话 B 的事务 COMMIT 之后,数据已经写到磁盘发生了变动(has been changed by another transaction),而此时 会话 A 又执行了查询操作,且此数据(original data, SNP_A_0 快照的数据)已经有了变动(queried data has been changed),故而 undo log 存储区域会重新构建(reconstructed) 一个快照——此处称其为SNP_A_1,此时间点的快照是包含会话 B COMMIT的数据的。
需要注意的是,此处的数据变动是 会话 B 与 会话 A 共同作用的结果,单独任何一方的操作在各自事务内是不会导致查询的数据有变化的。此案例中,会话 B 如果没有 INSERT a 为 4 的数据,那么 会话 A 的 UPDATE 执行会报错,是万万不能 UPDATE 成功的。正是这两者的结合,外加 MVCC 读视图快照的创建策略,原先数据(original data)的变化在读操作(SELECT 查询)的触发下重新构建快照。故而才会出现前后两次查询结果集不一致——幻读。
扩展:
更进一步的说,要达到数据读、写的强一致、同时又要达到高效率的并发。这在任何系统下都是矛盾的。读与写的一致在串行时是可以保证的,但往往串行了,并发就保证不了了。一条数据要同时多读、多写且用时短、效率高,想想都是很难。即使如此, MySQL 提出的 MVCC 策略使用了无锁定的、多版本一致读,虽然其未解决读写一致性,但这已经大大的提高了并发的效率,毫无疑问,这在某些场景下是一个极好的方案——(研读这些文档后,真诚的、发自内心的彩虹屁(」゜ロ゜)」~~)。
另外,JVM 多线程运行过程中从主存读取数据到各自线程私有的运行栈中,也有异曲同工之妙!
如果要保证此案例不会发生幻读现象,一种可行的方案是加锁,使用 SELECT ... FOR UPDATE 语句,如此会话 A 在事务内是持锁查询的,会话 B 是绝不会 INSERT 成功的——它只能眼巴巴的等着会话 A 事务结束后释放锁,而自己再持有锁时才能再操作,或者使用 NOWAIT ,不进行获取锁等待,直接放弃操作。有关锁,请参考:InnoDB Locking。
其他隔离级别下的读现象可如以上案例进行逐一验证,限于篇幅,此处不叙。
7. 参考
- MySQL Docs
- MySQL Reference Manual - InnoDB Architecture
- MySQL Reference Manual - InnoDB and the ACID Model
- MySQL Reference Manual - Statements That Cannot Be Rolled Back
- MySQL Reference Manual - InnoDB Locking
- MySQL Reference Manual - Transaction Isolation Levels
- MySQL Reference Manual - Autocommit, Commit, and Rollback
- MySQL Reference Manual - Consistent Nonlocking Reads
- MySQL Reference Manual - Locking Reads
- MySQL Reference Manual - Phantom Rows
- MySQL Reference Manual - InnoDB Multi-Versioning
- MySQL Reference Manual - Undo Logs
- MySQL Reference Manual - Redo Logs
- MySQL Reference Manual - SET TRANSACTION Statement
- MySQL Reference Manual - START TRANSACTION, COMMIT, and ROLLBACK Statements

